Data Validation Screen
Data Validation ensures that the data captured has undergone quality control so that the data is both correct and useful. Sequentum Enterprise makes data validation simple and easy through a centralized screen where every field can be configured to ensure quality. The purpose of validation is mainly important in terms of reducing the manual data checks once an agent is deployed and running on a schedule. It ensures that the data is correct, both in format and in content.
By defining validation rules , we can ensure the data quality is always maintained in an automated way. Under the Data tab, click on Validation Rules to adjust validation settings.
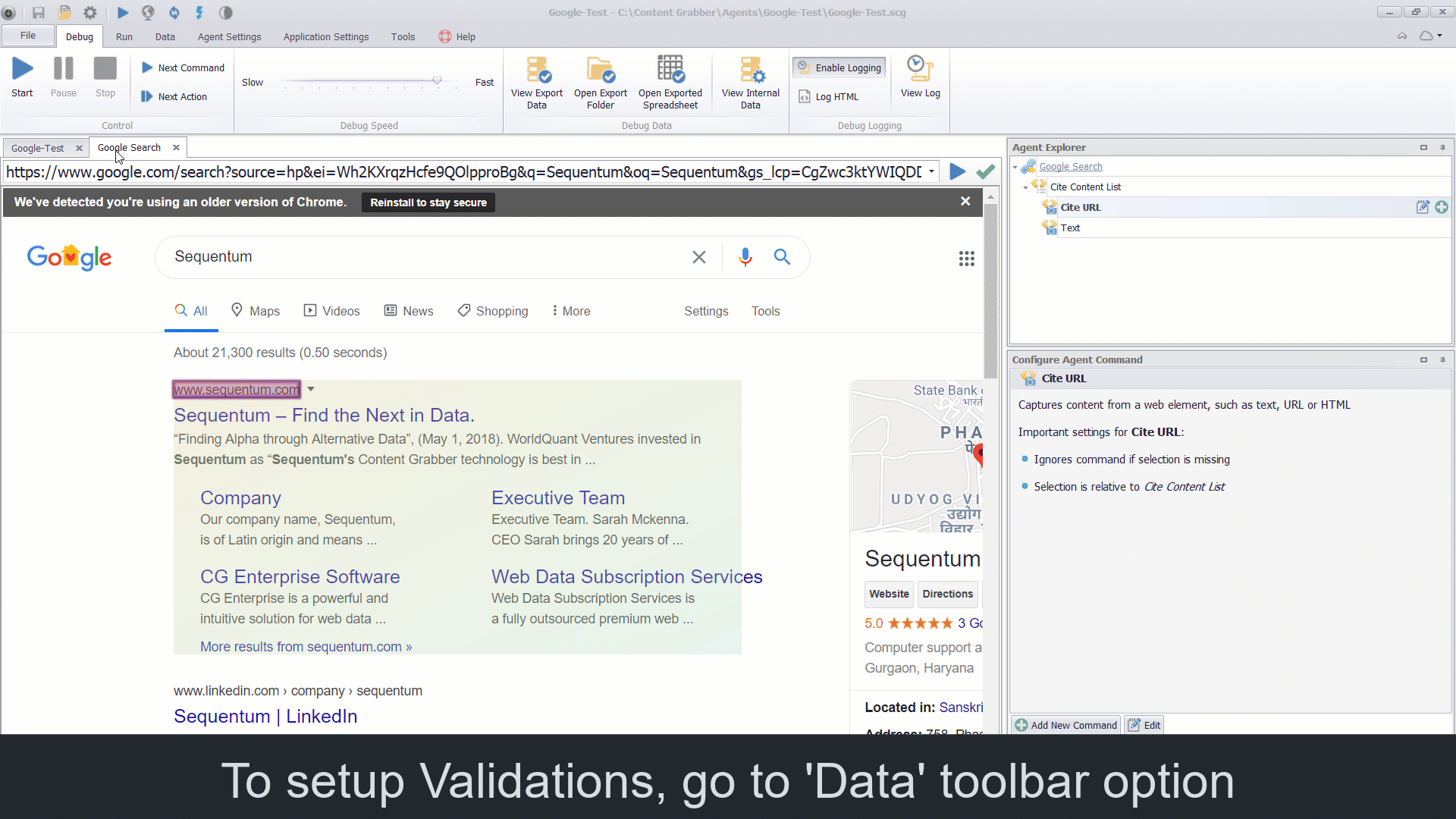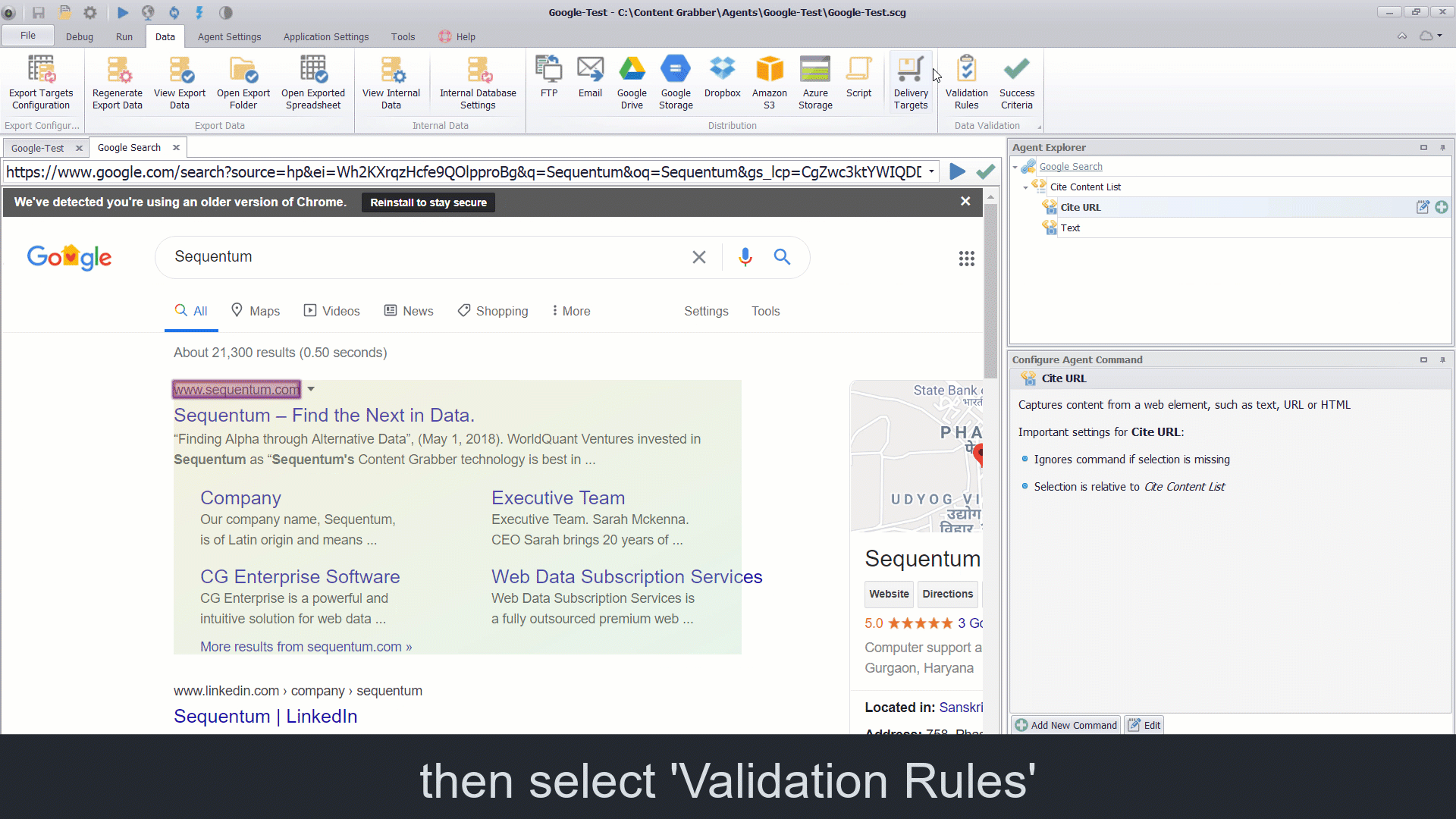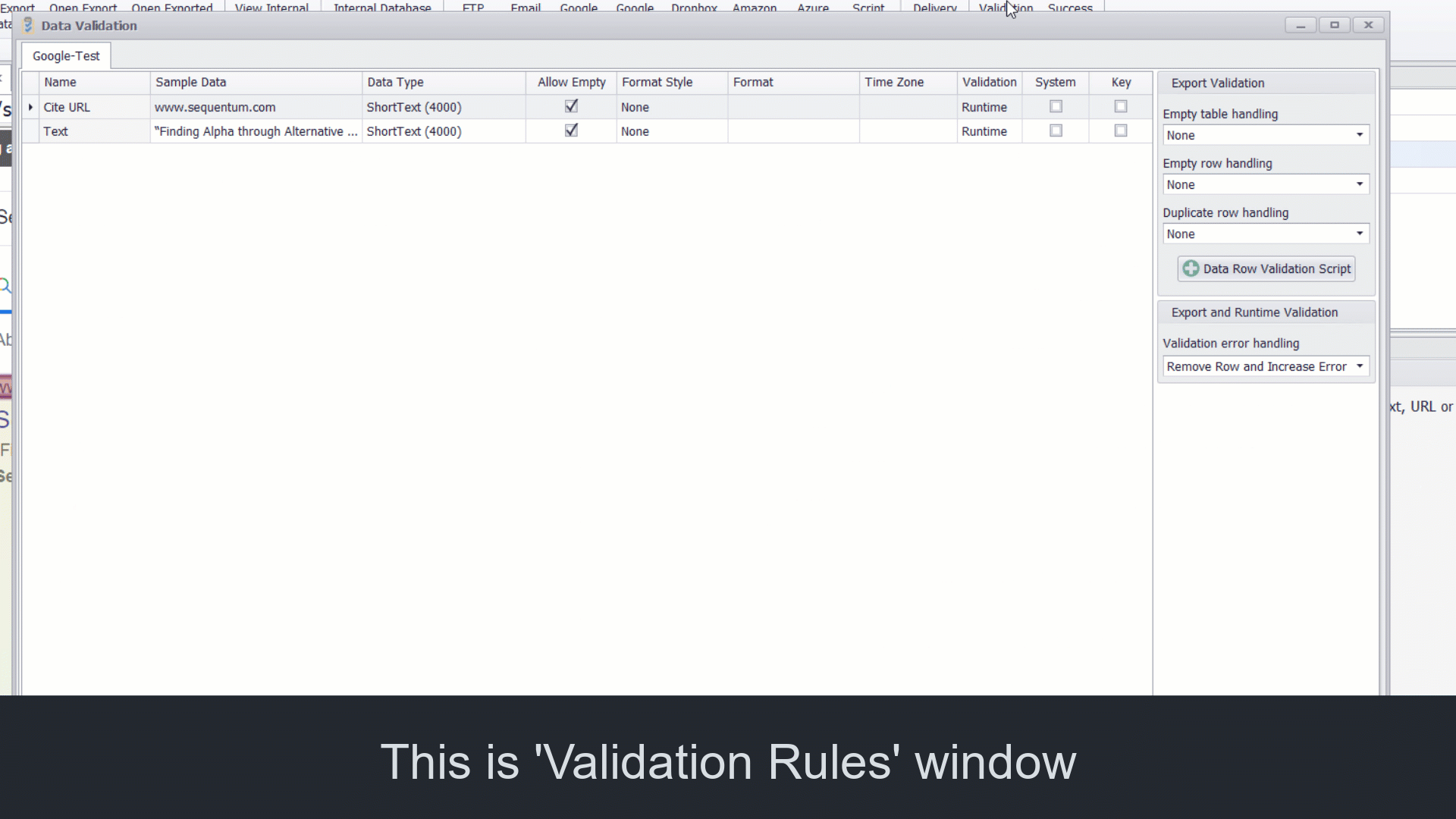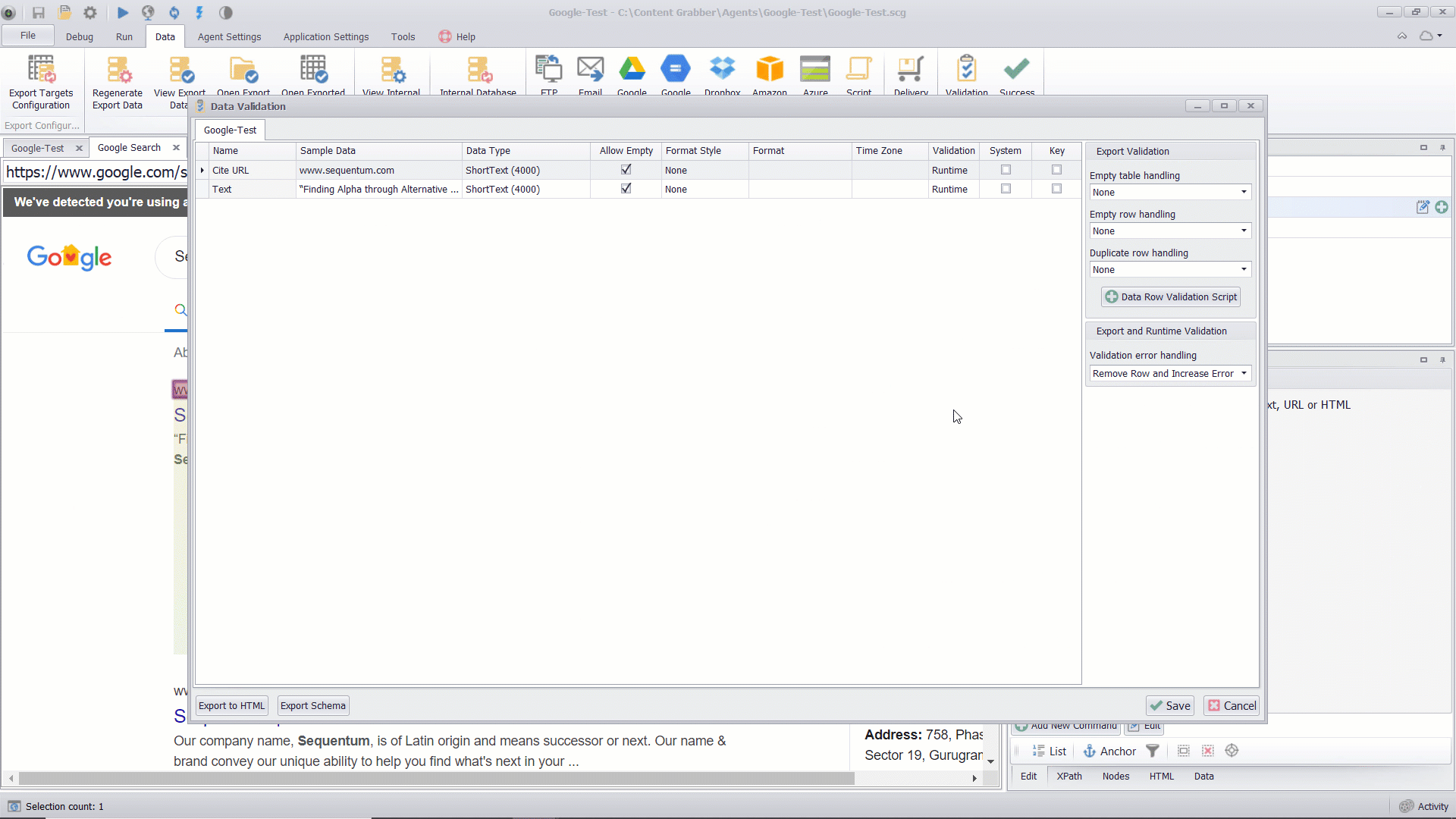
Data Validation Screen
By default, all the data columns in the agent are configured to perform the validation at Runtime which means that the data checks will happen when the agent is collecting data. The Validation rules can be applied on every single output column of the agent, by adding data checks such as data type and data length, allowing empty or non empty data check, system value check, key column selection for duplicate data check.
Additionally, the Export Data Validation rules can also be applied for the empty table handling or empty row handling or the duplicate row handling. The Export Validation rules can either be set to trigger export failures or remove the export rows and remove the export table or can be set to remove the export rows with the error in the logs or can be set to perform no export validation.
You can set the agent Success Criteria to pass or fail an agent and can also set the Error Notifications over email if the validation fails for any one of the column or export data as per the Validation settings.
Data Types
Sequentum Enterprise supports the following data types for captured data:
Data Type | Description |
Short Text | All content will be captured as Short Text by default. Short Text content can be up to 4000 characters long. |
Long Text | Long Text content can be any length, but cannot always be used in comparisons, so you may not be able to include Long Text content in duplicate checks. |
Integer | A whole number. |
Float | A floating-point number. |
Date/Time | Date and/or time value. |
Boolean | A value that can be true or false. Boolean values are stored as 1 or 0 integer values. |
Binary | A variable-length stream of binary data ranging between 1 and 8,000 bytes |
Big Integer | A 64-bit signed integer. |
Decimal | Represents a decimal floating-point number. A fixed precision and scale numeric value between -10 38 -1 and 10 38 -1. |
GUID | A globally unique identifier (or GUID).A GUID is a 128-bit integer (16 bytes) that can be used across all computers and networks wherever a unique identifier is required. Such an identifier has a very low probability of being duplicated. |
Document | The captured data is a document in binary form. This can be used in capture commands that stores a downloaded document from the web. |
Image | The captured data is an image in binary form. This can be used in capture commands that stores a downloaded image from the web. |
Allow Empty
Specifies whether the captured column can be empty or not.
Format Style
specifies the style of data format for captured content. Default value is set to ‘None’. Data captured can be formatted into the following styles:
None: Default style of data format.
Regular Expressions: Specifies the style of the data format using Regular expressions.
Examples:
Name | Data Type | Format Style | Format |
|---|---|---|---|
UrL | ShortText(200) | Regular Expression | ^.{1,200}$ |
CategoryID | ShortText(100) | Regular Expression | ^[a-zA-Z0-9]$ |
Date/Time: Specifies the style of data format for date and time.
Numeric Value Range: Specifies the style of data format as a range number.
JSON : Specifies the style of data formatfor JSON.
Name | Data Type | Format Style | Format |
|---|---|---|---|
Specifications | ShortText(2000) | JSON | {} |
Format
Formatting acts as a form of validation. It ensures both that the data collected is of the correct type and the desired format for export.
For example, you could specify DateTime to be formatted as YYYY-MM-DD.
Time Zone
If a captured data is defined as a date/time, a time zone can be used to determine what time zone the data was collected in. The following are selections for time zone:
Assume Local Time
Assume Universal Time
Adjust to Universal Time
Validation
The Validation on a specific data column can be specified to perform the validation during Runtime or Export or Runtime And Export.
By default, all the data columns in the agent are configured to perform the validation at Runtime which means that the data checks will happen when the agent is collecting data. The Validation can be changed to Export or Runtime and Export for each individual data export column directly from the Data Validation window or can be changed from the individual export column property.
The Export validation is performed when the agent starts exporting the data to the export table.
Runtime And Export validation is performed during agent runtime execution and also during the export time when the agent is exporting the data to the export table. The latter facilitates providing an additional data validation check on the data quality of the agent.
System
System value that is guaranteed to be present, and does not participate in an empty data row check and system values are not present in the internal database.
For example, if you set RunId in an agent, then it can set as a System column as this column will always have the auto generated data by the system and can be ignored when performing empty row validation.
Key
A key column is used to uniquely identify a data entry. Multiple capture commands can be marked as key columns to combine extracted data from multiple commands into a value that uniquely identifies a data entry.
Export Validation:
Export Validation is executed during the data export. It is used to handle empty tables, empty rows, and duplicate rows at export time.
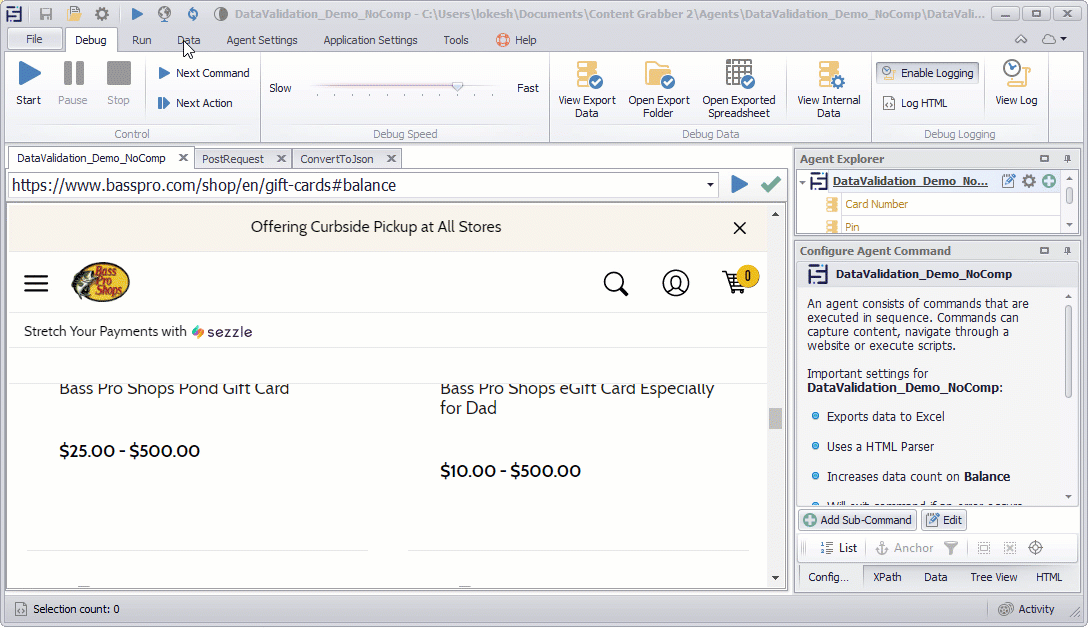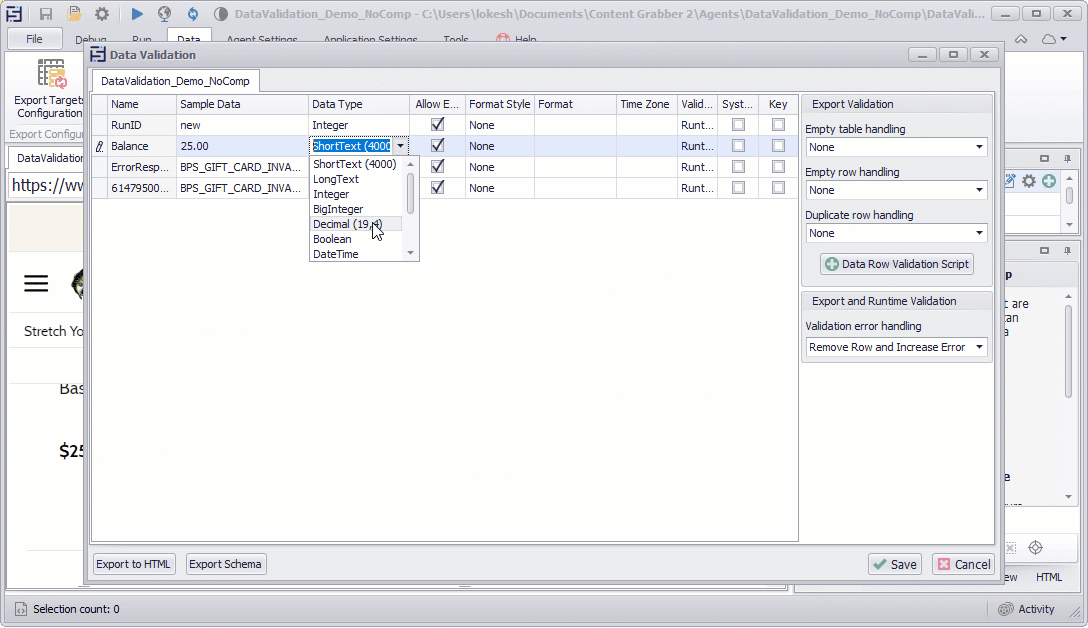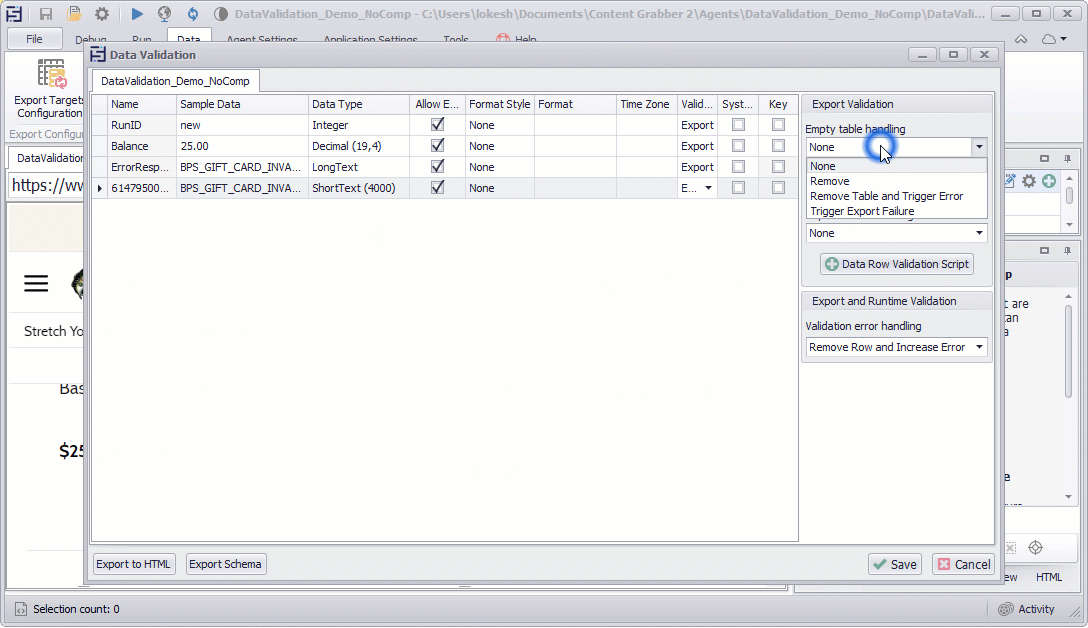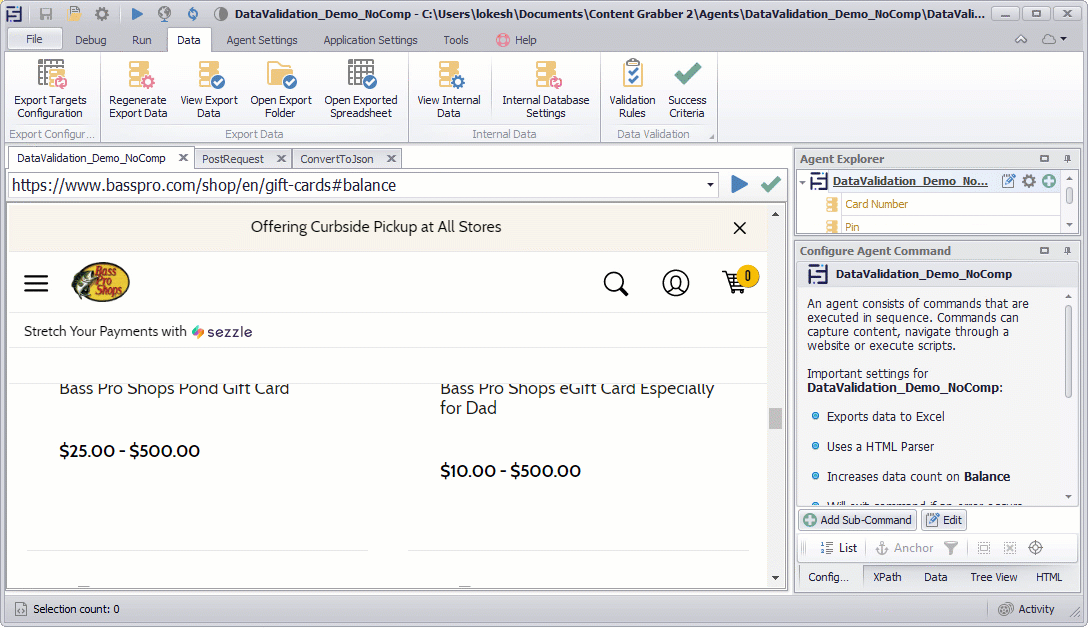
Empty table handling:
Specifies what action to take when an export data table is empty. The default value is set to None.
None: Do nothing when there is an empty data table and the same empty table will be exported as a result file.
Remove: This is used to remove the empty data table from the export data .
Remove Table and Trigger Error: This is used to remove the empty data table from the export data and also trigger the error when there is an empty data table.
Trigger Export Failure: This is used to trigger an export failure when an export data table is empty, so an agent will fail and an empty result file will not export.
Empty row handling:
Specifies what action to take when an export data row is empty. If removing empty rows, all child data of an empty row will also be removed, even if the child data is not empty. Capture commands with the property System as checked are ignored when checking if a data row is empty. The default value is set to None .
None: Do nothing when there are empty rows.
Remove Row: This is used to remove the empty rows from the export data when there are empty rows.
Remove Row and Increase Error: This is used to remove the empty rows from the export data and also increases the error count when there are empty rows.
Trigger Export Failure: This is used to trigger an export failure when there are empty rows, so an agent will fail and a result file with empty rows will not export.
Duplicate row handling:
Specifies what action to take when duplicate data export rows are detected. All child data of a removed row will be assigned to the existing duplicate row. The duplicate check can be performed on values extracted by Capture commands with the key property, or it can be performed on hash keys calculated from all values in an export data row. The default value is set to None .
Note: If there is a Key column defined, the key will be used to determine a duplicate row, otherwise if there is no Key defined, the hash value (SHA 512) of the entire row is used to determine a duplicate.
None: Do nothing when there are duplicate rows.
Remove(SHA-512): This is used to remove Duplicate rows when an agent runs in a single session.
Remove(Key Values): This is used to remove Duplicate rows when an agent runs in a single session.
Remove(Key Values Across Sessions) : This is used to remove Duplicate rows when an agent runs in Performance Sessions.
Data Row Validation Script
The validation script provides additional flexibility to validate every single data row before it is exported. For example if you want to normalize the extracted US State Names to 2 letter code in your output data, you can use the validation script to make sure that your State Name column is always validated and Normalized to output a 2 letter state code. Similarly, you can apply validation for normalizing phone numbers or Zip codes to follow a specific format every time the data is extracted and exported.
Export and Runtime Validation
There are different validation error handling options that can be applied to the agent. These error handling options work on the basis of “Validation” option settings e.g. if we set the “Validation” as “Runtime” then these validation error handling actions are performed only at run time.
None : Do nothing when there is a data validation error.
Remove Row : Removes the row from the export data when a data validation error occurs.
Remove Row and Increase Error: Removes the row from the export data and also increases the error count when a data validation error occurs.
Trigger Failure: Triggers an export failure when a data validation error occurs, so an agent will fail and a result file with incorrect data due to data validation will not export.
Export Schema
The Data validation window allows you to export the schema using the settings on the Data Validation screen. See the Data Validation Schema topic to learn how to use the agent schema file in Sequentum Enterprise and AgentControlCenter.
Use the following code to read schema in Export Script:
string schema = args.GetExportSchemaAsJson();
Export to HTML
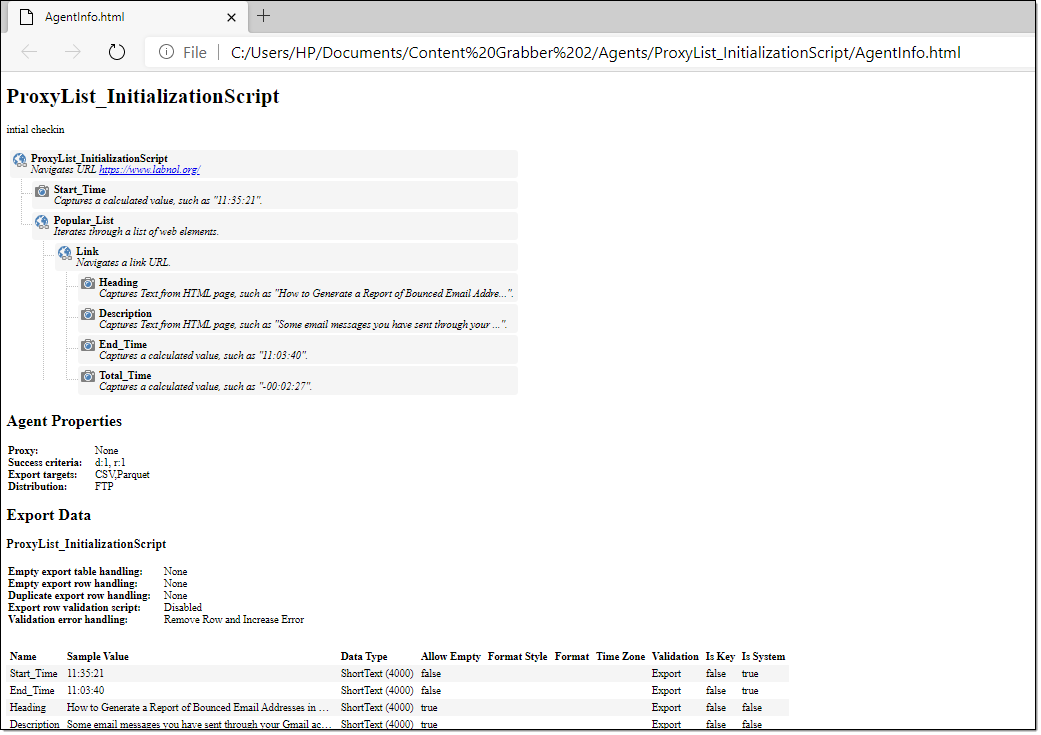
The Data validation window allows you to export the agent information using the settings on the Data Validation screen. It saves all the agent information in an HTML file such as agent command names with description, data validation settings, Success criteria details, proxy details, export target information. Under the Data menu, click on Validation Rules and then click on the Export to HTML button to save the agent information as an HTML file in the agent root folder.
Example of Export to HTML as an AgentInfo.html file: