
Web Scraping on Modern Websites – Part 3
This article is the third part of blog series as the first part is Fast and Reliable Web Scraping on Modern Websites in which we have shown you the fastest and most reliable way to extract data from a website and the second part is Web Scraping on Modern Websites – Part 2 in which we have covered when you need to generate complex web requests to get data out of the Web API. I recommend you to go through these two articles before reading this.
In this article I will show you how to deal with the websites containing Cross-Site Forgery Tokens (CSRF) which is a secret, unique and unpredictable value a server-side application generates in order to protect CSRF vulnerable resources and is a common roadblock encountered during web scraping. This token is unique per user session and should be of large random value to make it difficult to guess.
Generating Complex Web API Requests containing CSRF tokens
Creating secure web API requests involving CSRF tokens is a two-step procedure. Initially, you must identify and analyze the web requests that the website sends to the API, including the crucial CSRF token. Afterwards, you can leverage this information to craft your own requests while ensuring proper CSRF token inclusion.
The detection and examination of these web requests can be accomplished using tools like Fiddler, Web Browser developer tools, or specialized web scraping software such as Sequentum Enterprise. This process shares similarities with the approach discussed in my earlier article, but it also requires a specific focus on the web request headers and the inclusion of the CSRF token when interacting with the Web API.
Understanding the Challenge: CSRF Tokens
Before we go through the solution, let's first understand what CSRF tokens are and why they are a significant challenge for web scraping.
CSRF tokens, short for Cross-Site Forgery Tokens, are security measures employed by websites to prevent unauthorized actions or requests from being made on behalf of a user without their consent. They are used to verify that a request or action initiated on a website originates from a legitimate source, typically by embedding a unique token within the website's forms. When a user submits a form or performs an action, the CSRF token is checked to ensure that it matches the expected value. If not, the request is rejected, thereby throwing potential attacks.
Challenges with CSRF Tokens in Web Scraping
For web scrapers, CSRF tokens pose a considerable obstacle. Since the primary purpose of a scraper is to automate data retrieval, it operates independently of the typical user interactions that trigger the generation of CSRF tokens. When a scraper attempts to access a website, it often lacks the necessary CSRF token, resulting in rejected requests and failed scraping attempts
An Example
Consider the website https://www.myschools.nyc/en/schools/pre-k/ , which specializes in finding information and applying for pre-kindergarten (pre-K) programs, as an instructive case in dealing with complex Web API requests containing CSRF tokens.
Diverging from the more straightforward grocery website covered in my earlier article,http://shopwoodmans.com employs an advanced method: asynchronous data loading. As you scroll down the page to access additional products, it dynamically fetches and displays data. Although many high-quality web scraping tools can not handle this scenario without the need for direct Web API requests, this approach often presents challenges, performs slowly, and may yield inconsistent results. Consequently, this website provides an excellent opportunity to illustrate the advantages of opting for direct Web API requests, especially in the context of CSRF token handling.
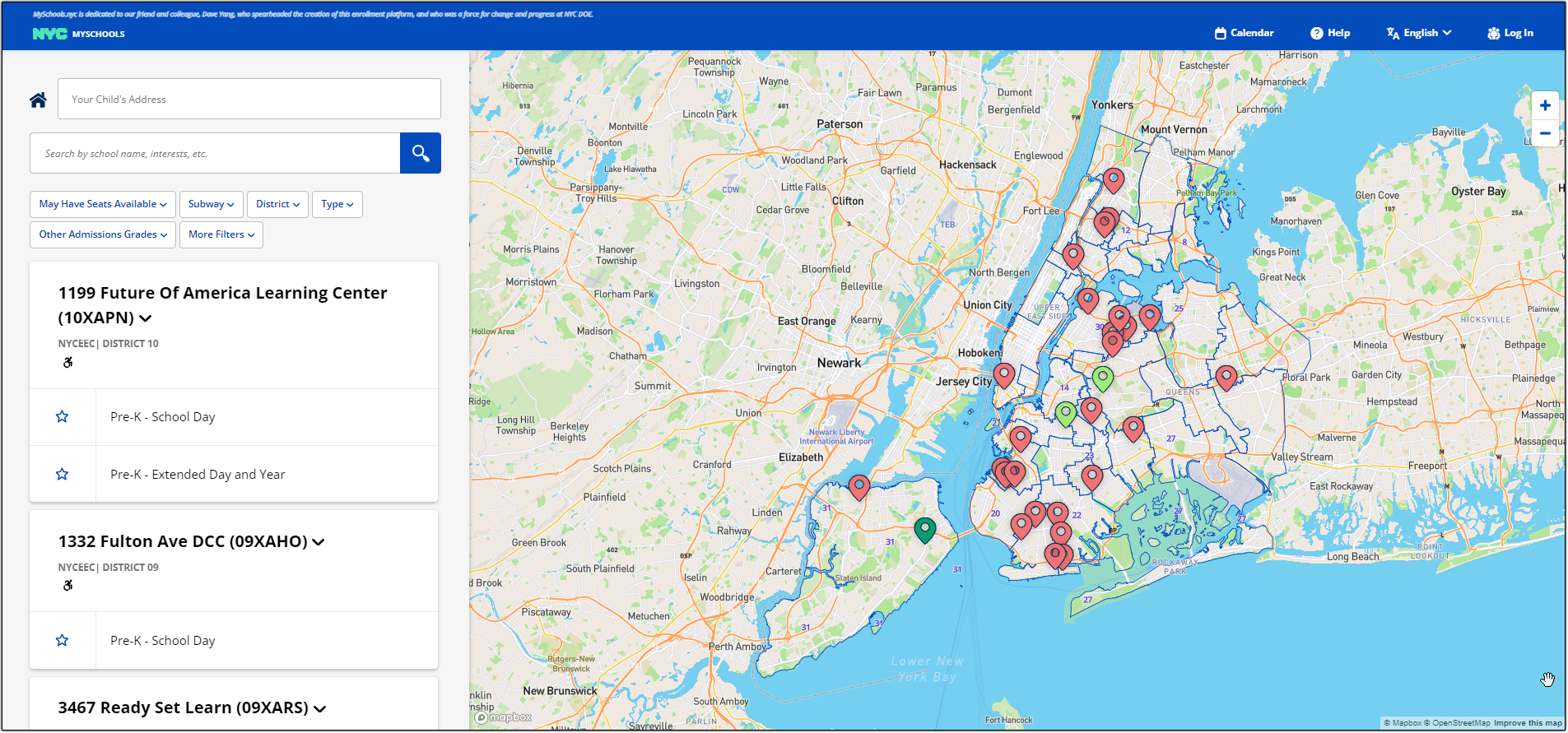
On this website products are loaded asynchronously as I scroll down the page
Just like in my last article, I've explained how to examine web requests using Sequentum Enterprise because it's really good at helping you to check, create, and test complex web requests.
Initially, I'll open the website in Sequentum Enterprise, and after that, I'll scroll down to the school list to make the Web API requests that bring in additional data.
I’m looking for web requests that will return JSON
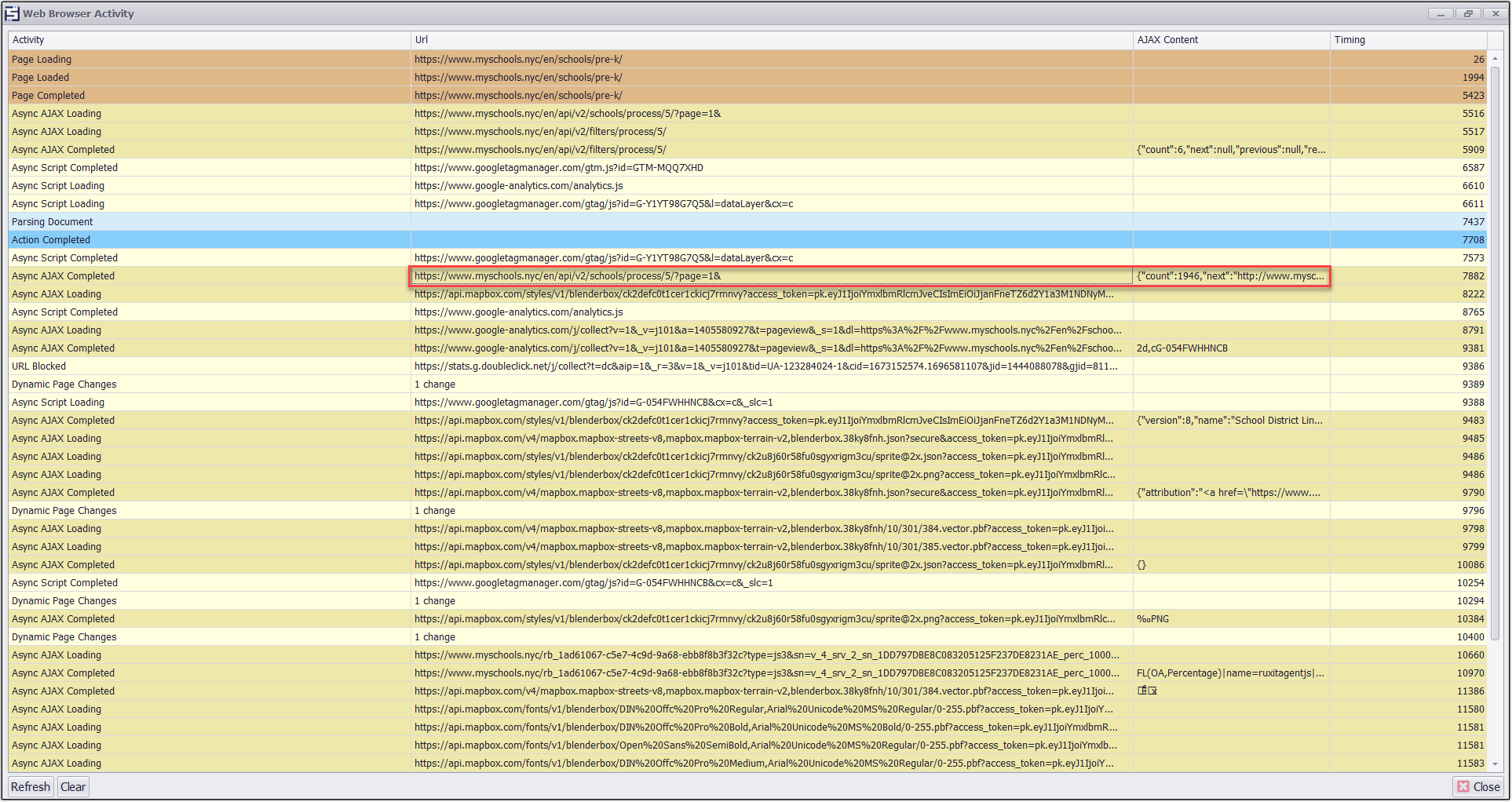
Now I will access the Browser Activity screen within Sequentum Enterprise to search for Web API requests that are relevant to my needs.
https://www.myschools.nyc/en/api/v2/schools/process/5/?page=1&
I will now double click on the URL to get the web request editor window through which I can test the entire Web Request with the URL and also see the headers and post data present in it.
Here we can see in the headers section that we are getting the CSRF token under the cookies section.
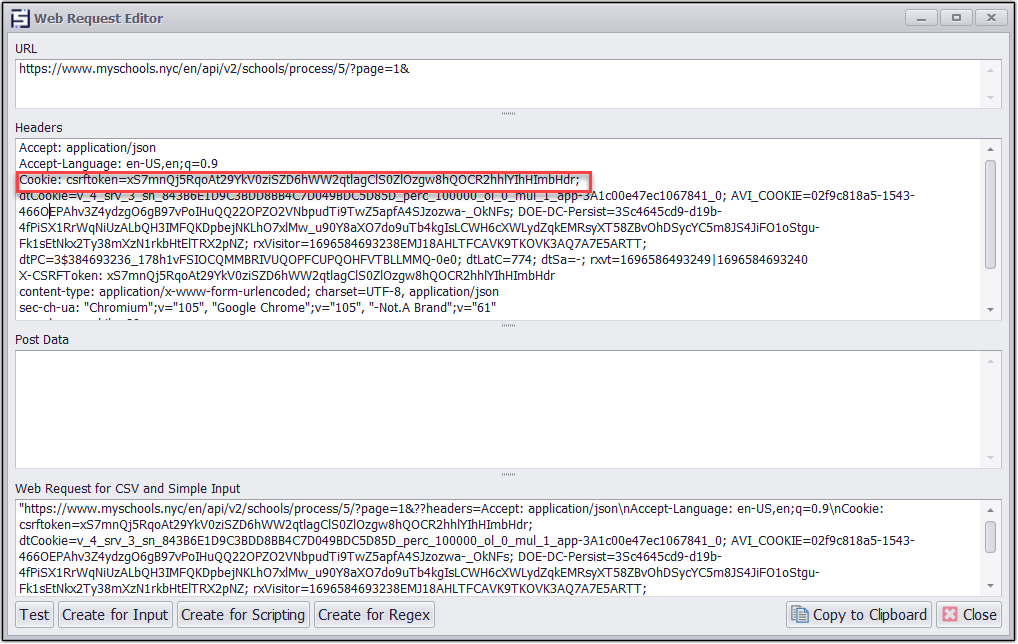
In the headers section CSRF token is visible.
Sequentum Enterprise uses specially formatted URLs to incorporate CSRF tokens, headers, and post data into a web request.
"https://www.myschools.nyc/en/api/v2/schools/process/5/?page=1&
??headers=Accept: application/json\\nAccept-Language: en-US,en;q=0.9
\\nCookie: csrftoken=UfQQZKi3bkQK9pMfBVJLWERxpfeq0u92X5hgRIjTrbooMIYRZtcgOQmJrnFYIT9z;
dtCookie=v_4_srv_2_sn_0EF5B11BCDEE0B6F68DB5D28D8B49C21_perc_100000_ol_0_mul_1_app-3A1c00e47ec1067841_0;
DOE-DC-Persist=3Sc4645cd9-d19b-4fmbmkCkER73gkeQ5Y4DFeGOhwEkdZy-9jCRzDDI_xZrdILHf4uX-XB7TOWBmL4fm8JR1cRdghSFDrm57rvAP1AS7UCdjQZIPM77IH0T02JS6tgCzDUp8RDlnPMSTBXgdpLBt2lsDb4Awl4ToK; rxVisitor=1694866943234AE61F2RRFUIEO1CDEC2MBJEGGLUMRKME;
dtSa=-; _gid=GA1.2.41182290.1694866947; _ga=GA1.1.719719221.1694866947; _ga_Y1YT98G7Q5=GS1.1.1694866946.1.1.1694866986.0.0.0; _ga_054FWHHNCB=GS1.2.1694866947.1.1.1694866986.0.0.0; AVI_COOKIE=02f859adb6-c114-45jESIjHL5A8TLH-ZLcLHJ-wk_Cq6FrdYE4ZpRUJIYZaVphKXExffDmH08rl6DpJnu68k;
AVI_COOKIE=02f859adb6-c114-45RJQwJGjRA4d1VNUvl30nXSCPdYXfzm9YPUMg71n4MGbNi5UU1SZlsDAAV4lCn-YlFBs; dtPC=2$478568854_408h1vUAURHKFQPIVDHBFNUSSLBPPMBJNUPPRG-0e0; dtLatC=953; rxvt=1694880368861|1694876931493\\nX-CSRFToken: UfQQZKi3bkQK9pMfBVJLWERxpfeq0u92X5hgRIjTrbooMIYRZtcgOQmJrnFYIT9z
\\ncontent-type: application/x-www-form-urlencoded; charset=UTF-8, application/json
\\nsec-ch-ua: \" Not-A.Brand\";v=\"93\", \"Chromium\";v=\"105\", \"Google Chrome\";v=\"105\"
\\nsec-ch-ua-mobile: ?0
\\nsec-ch-ua-platform: \"Windows\"
\\nReferer: https://www.myschools.nyc/en/schools/pre-k/"You can directly load the URL into Sequentum Enterprise, just like any other URL, and Sequentum Enterprise will automatically include the specified CSRF tokens, headers, and post data.
Creating the Sequentum Enterprise Web Scraping Agent
I’ll create a Sequentum Enterprise web scraping agent that generates and loops through a number of web requests with increasing page numbers. I don’t know exactly how many pages of products are available on the website, so I’ll just generate enough requests to make sure I get to all the available pages. Once a web request returns no product data, I know there are no more pages available and I can exit the loop.
Below are the steps to create the web scraping agent in Sequentum Enterprise.
Step 1
Create a new agent by using the URL “https://www.myschools.nyc/en/schools/pre-k/ ” and use it in the agent command. It will load the URL in Sequentum Enterprise and will be visible just like on any other web browser.
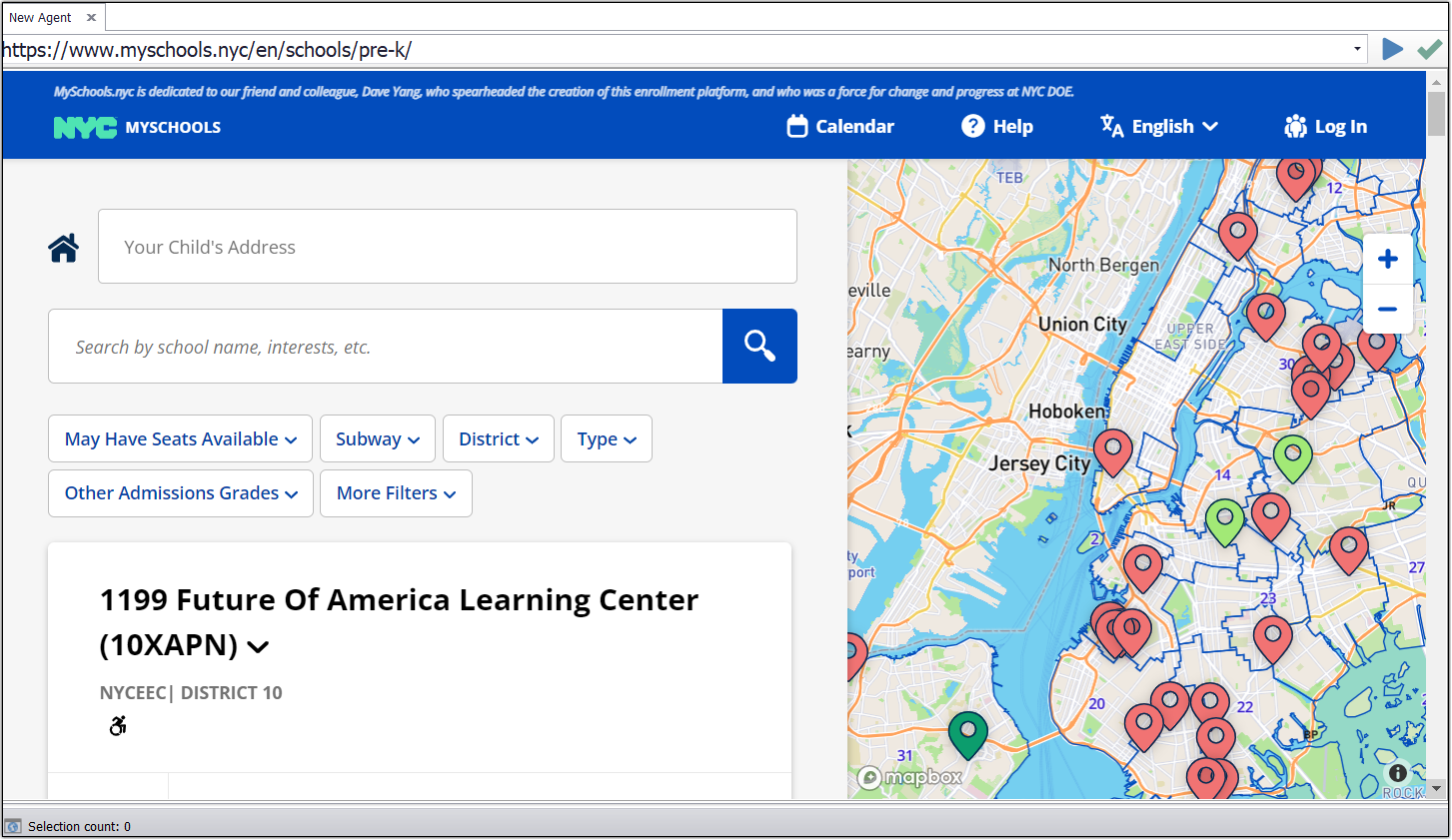
URL loaded in Sequentum Enterprise
Now open the activity window and search for Ajax Completed request which should be particularly for the 1st page load.
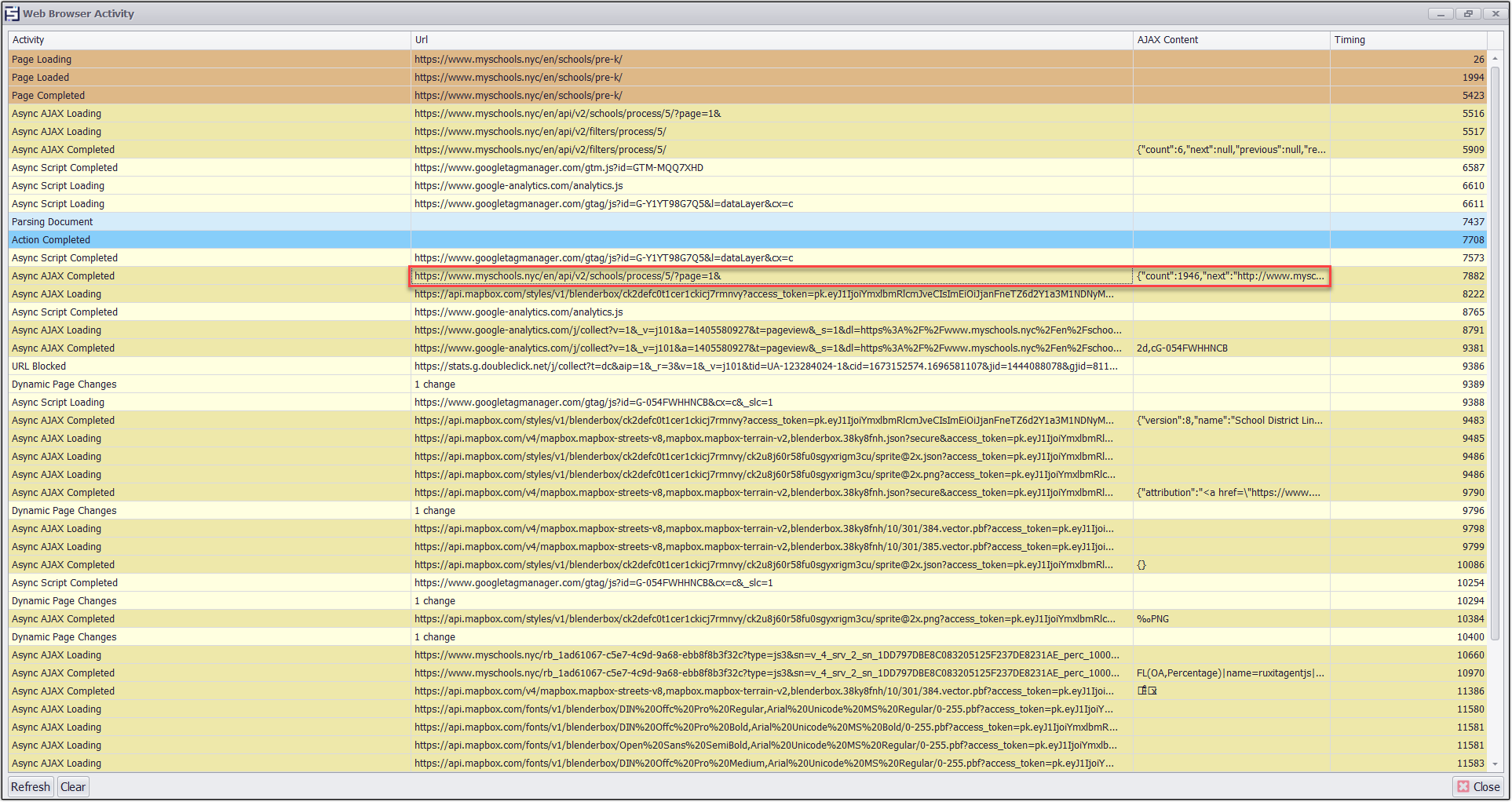
Ajax Request containing request for the 1st page load
This request contains the CSRF token as a cookie in the headers and it will be useful to load the page in JSON parser which should load the content and should provide data very quickly with the help of Sequentum Enterprise.
Step 2
Now we will create an input of the request and will use it in the Navigate URL command in the transformation script by setting browser type as JSON parser. This will load the page in JSON and will be loaded very quickly as compared to the dynamic browser.
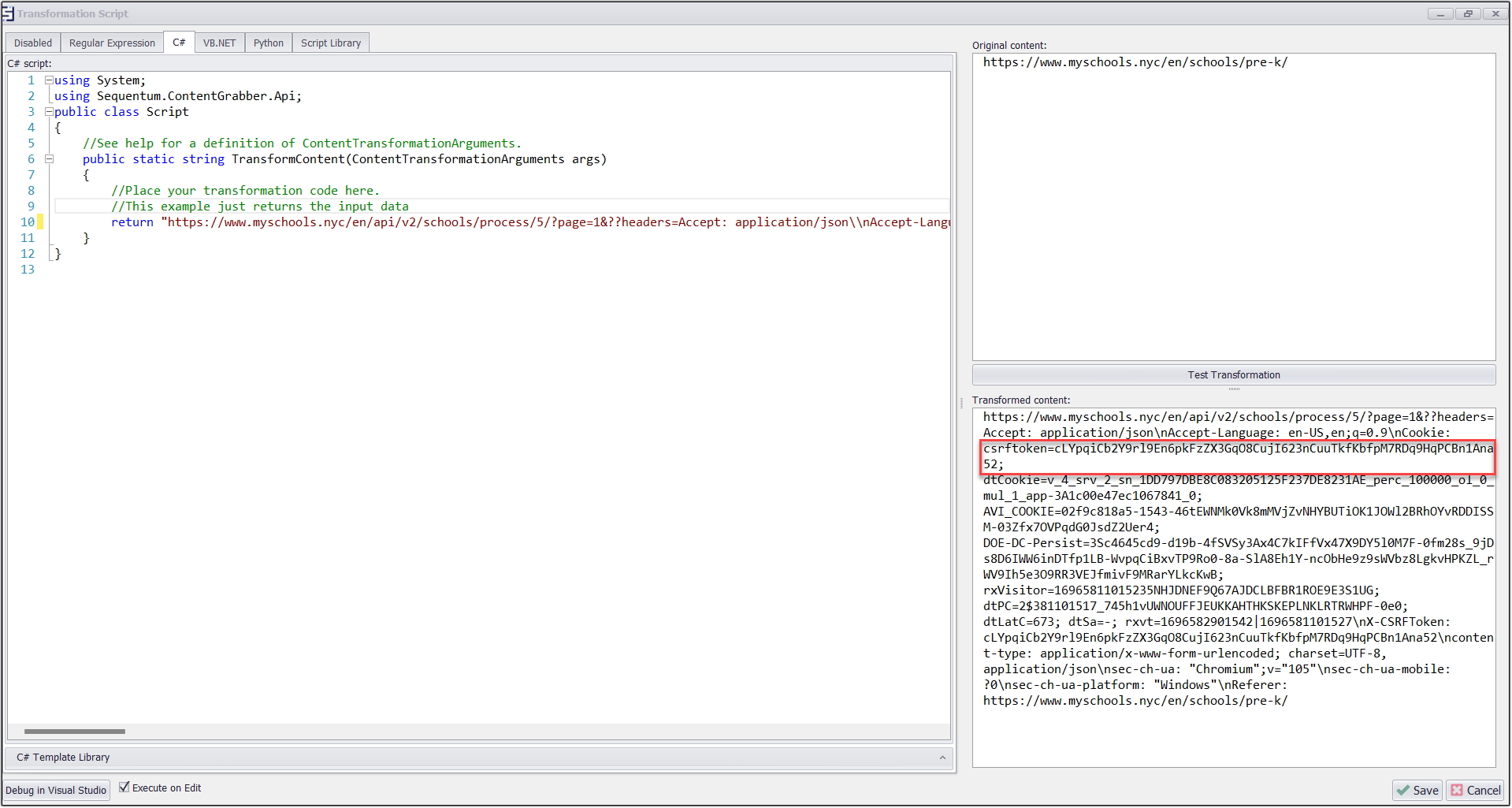
Here I have returned the request in the script
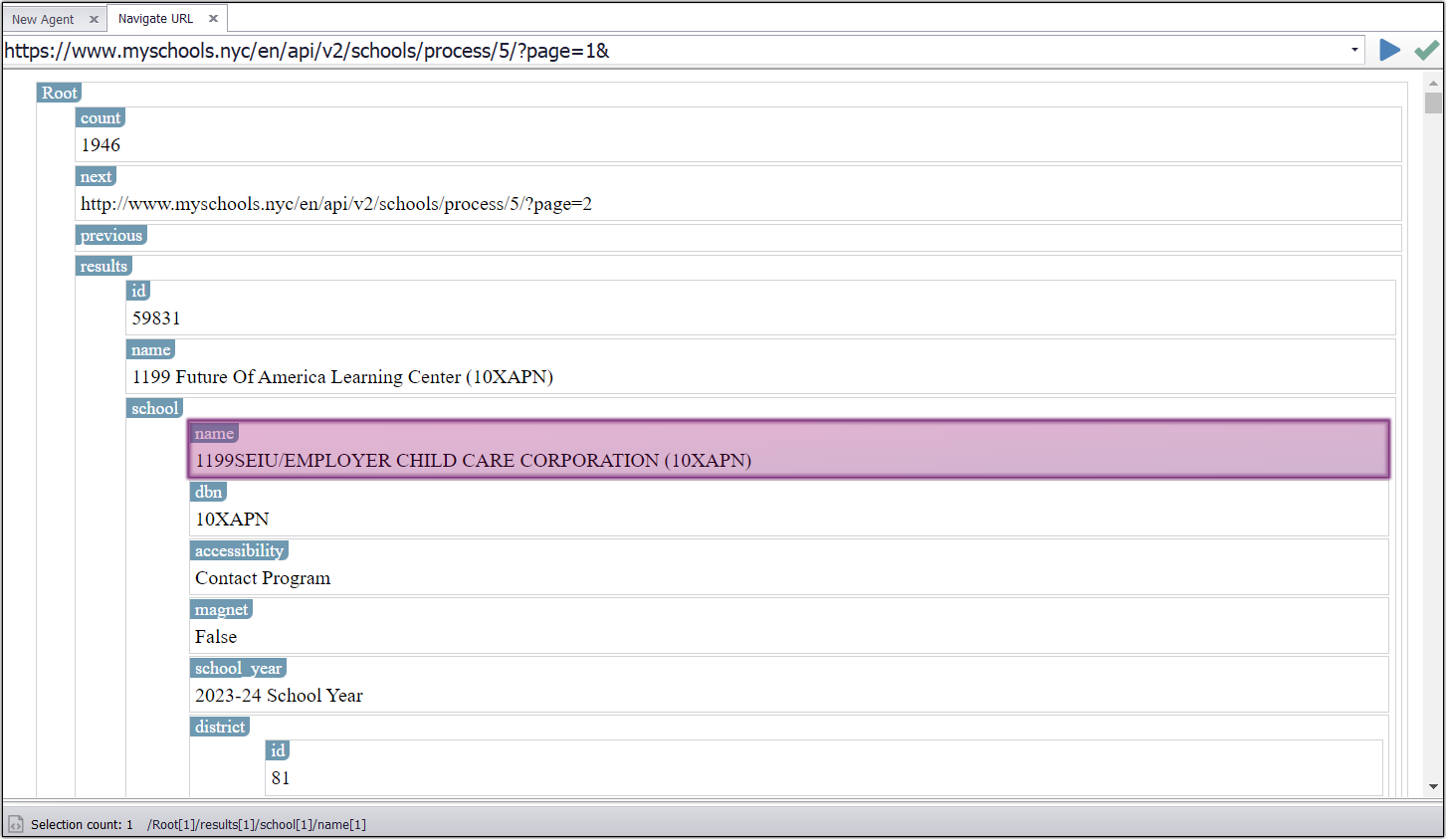
Request is loaded in JSON parser
Step 3
With the JSON data successfully ingested into JSON Parser, I can simply point and click to configure my agent to extract data from the JSON returned from the Web API.
After capturing the desired data my agent command looks like this
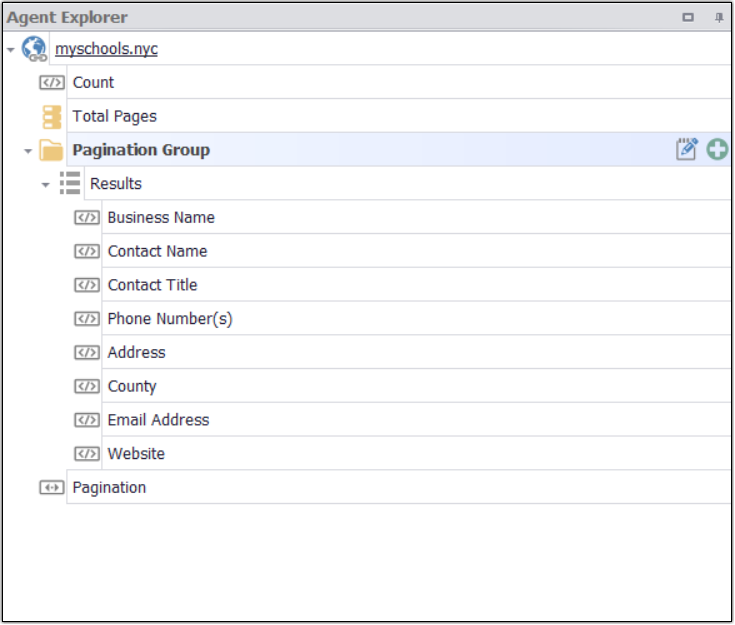
Command which i have added
Step 4
I have captured total count of schools from the web page and used it in Transformation Script under the data value command

Script for getting the total number of pages
In the above script we are getting total count by using the web content command i.e. “count” and it will be further used for the pagination command to ensure where to end the content scraping.
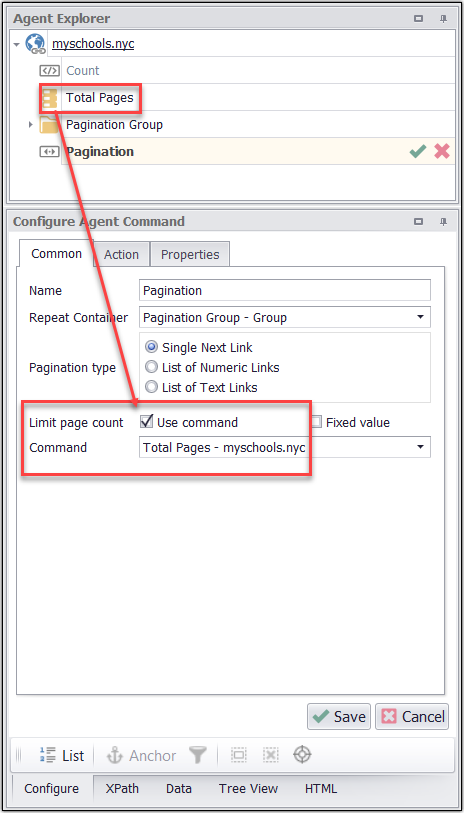
Settings for pagination command
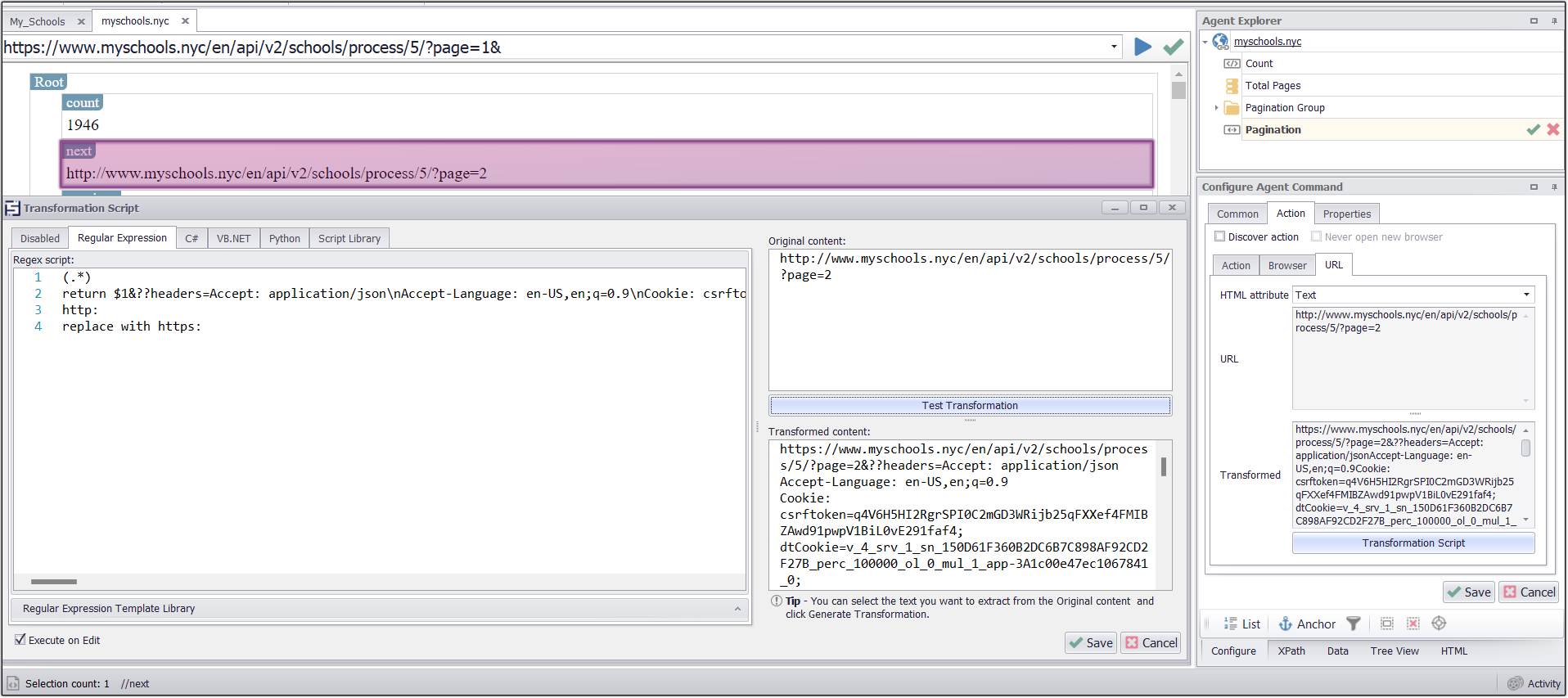
Regex used to get the page load
Let’s Run the Web Scraping Agent
I can now run the web scraping agent and the 1922 schools data are extracted in 4 min 58 seconds.
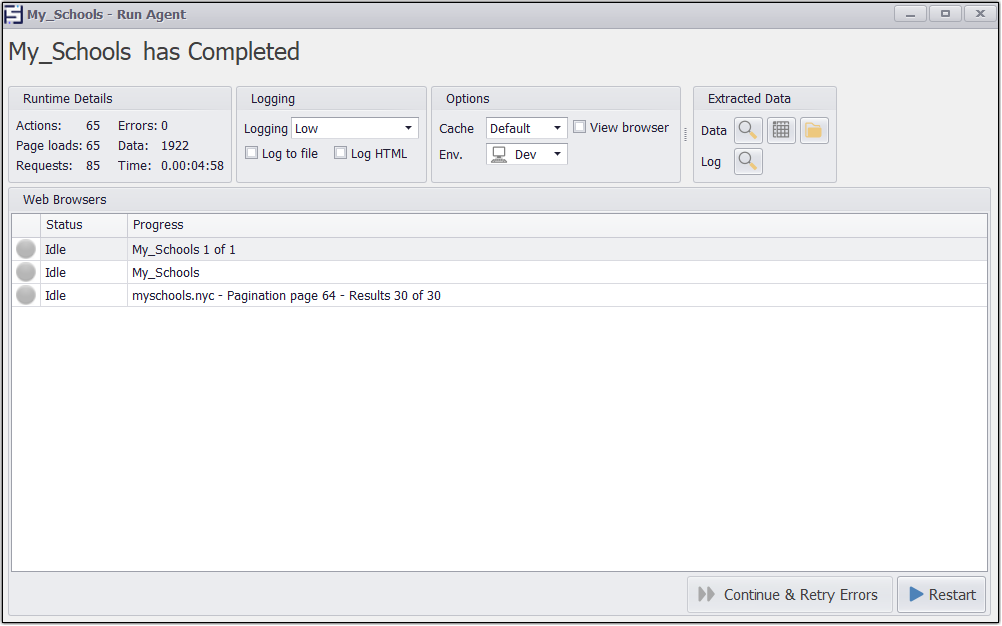
The agent extracts 1922 schools records in 4 min 35 seconds
This is how the acquired data appears when visualized in Excel.
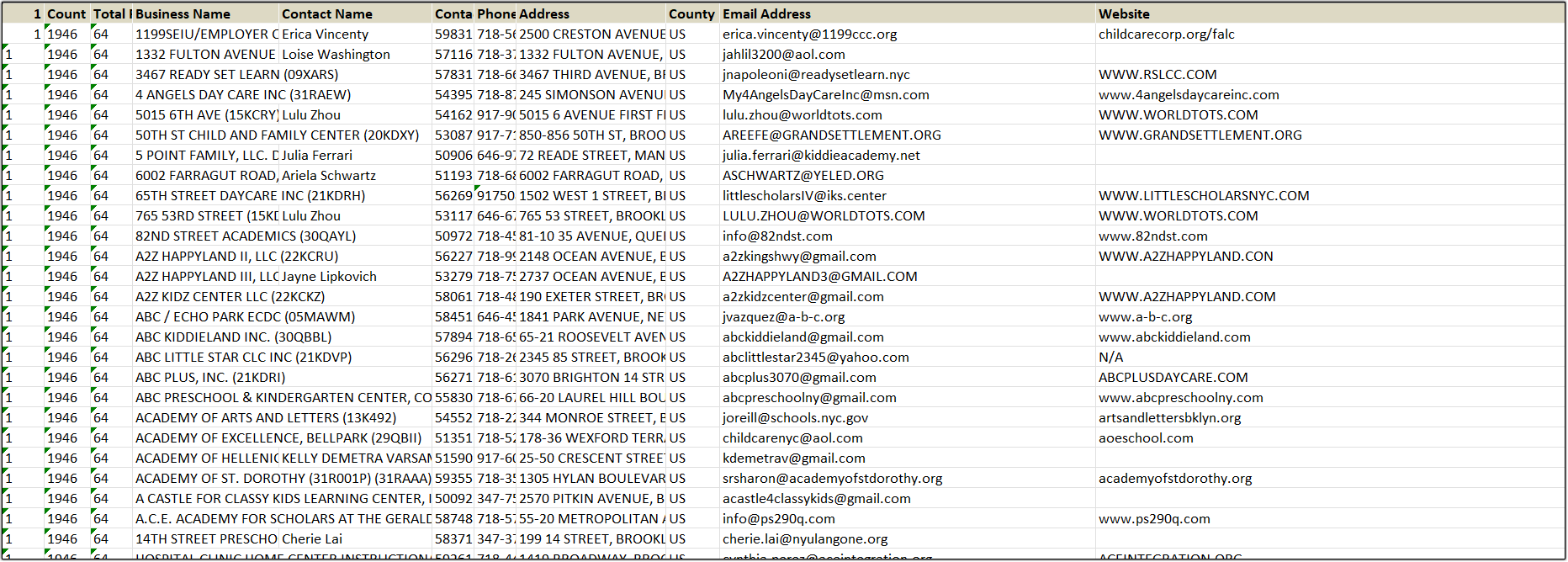
The extracted data in Excel format
Navigating CSRF Tokens: The Final Solution
To overcome CSRF tokens and successfully scrape data from websites like https://www.myschools.nyc/en/schools/pre-k/ , we need to simulate user interactions effectively. Here's a step-by-step guide on how to do it:
Analyze the Target Website: Begin by thoroughly inspecting the target website. Identify where CSRF tokens are used and how they are generated. This may require inspecting the website's HTML source code and examining the network requests made during user interactions.
Capture CSRF Tokens: Once you've identified the location and method of CSRF token generation, you can capture the token when a legitimate user interacts with the website. This may involve using browser developer tools to monitor network traffic and extract the CSRF token from requests.
Recreate User Interactions: To mimic a legitimate user, your scraper should now include code to replicate the actions that lead to CSRF token generation. This may include sending GET requests to load pages, extracting and storing the CSRF token, and then sending POST requests with the token when necessary.
Implement Session Management: To maintain continuity in your scraping efforts, it's crucial to manage sessions effectively. Use libraries like 'requests' in Python to handle cookies and sessions, ensuring that your scraper appears as a legitimate user throughout the scraping process.
Handle Token Expiry: CSRF tokens often have a limited lifespan. Keep an eye on token expiration and update your scraper to fetch new tokens when needed. This requires continuous monitoring of network traffic and adapting your code accordingly.
Rate Limiting and Politeness: To avoid overloading the website's servers and getting blocked, implement rate limiting and follow polite scraping practices. Respect the website's terms of service and robots.txt file to maintain a good scraping reputation.
Error Handling: Be prepared for errors and exceptions that may occur during scraping. Implement robust error-handling mechanisms to gracefully handle issues like token mismatch or temporary website downtime.
Conclusion
Scraping data from websites that contain CSRF tokens may seem challenging at first, but with the right approach and techniques, it's entirely achievable. In this article, we've explored the concept of CSRF tokens, their role in web security, and how to overcome them when web scraping. By understanding how CSRF tokens work and implementing the steps outlined above, you can effectively scrape data from websites like https://www.myschools.nyc/en/schools/pre-k/ and other sites that utilize the same method. Remember to always scrape responsibly and ethically, respecting the website's terms and policies, to ensure a seamless and productive web scraping experience.