
Fast and Reliable Web Scraping on Modern Websites
Everybody involved with web scraping knows how difficult it can be to extract data from modern websites. In this blog post, I’ll show you the fastest and most reliable way to extract data from a website. Once you have mastered this technique, you’ll come to love these websites, since this is "nearly" as fast and reliable as pulling data straight out of a database.
(Please note that you cannot use this technique with every website, but it’s worth checking before you start building a web scraping bot.)
The Problem with Modern Websites
Many modern websites use web frameworks that separate layout from data. JavaScript is used to generate the final web page you view in your web browser. When you open a modern website it often only loads some layout and JavaScript initially, and then loads the data asynchronously afterward and merges the data into the layout.
Simple web scraping tools that don’t execute JavaScript will not be able to extract data from these websites at all, and even advanced tools will have difficulties with many of these websites unless the web scraping bots are carefully created.
Advanced web scraping tools can use embedded web browsers to load websites and execute JavaScript, so they will be able to process most modern websites, but web browsers are very slow and are known to crash occasionally, so you should avoid using them whenever possible. Furthermore, many modern websites load data asynchronously, sometimes depending on how you scroll down a web page. High-end web scraping tools can deal with these scenarios, but it can be very difficult to create reliable bots for such websites, and they’re certain to be very slow.
The Solution
The solution lies in the asynchronous calls modern websites make to load data. The web server functionality that provides the data is often called a Web API, so the asynchronous calls are often referred to as Web API requests. The Web API normally provides structured data in JSON format which is very easy to work with, and the Web API requests are very fast compared to loading a full web page.
You can make the Web API requests without loading the full web page, and then just parse the returned JSON and save your data. The hardest part is figuring out how to call the Web APIs since they obviously don’t come with public documentation.
You can use many different tools to examine how a website uses a Web API. Fiddler is a popular tool, but you can also use the developer tools that exist in most web browsers, or you can use a dedicated web scraping tool such as Sequentum Enterprise. Once you know how a website uses a Web API, you can replicate that in your own program to extract the data.
A Simple Example
In this example, I’ll extract data from the website https://www.grove.co/home which is a highly dynamic website that loads data from a Web API.
The target website is a Health home essentials website that has many categories of products, but to keep this example simple I’ll extract data from just one category. It’s relatively easy to extend the web scraping bot to extract data from all categories on the website.
First I’ll open the website in the Sequentum Enterprise editor and navigate to the category I’m interested in.
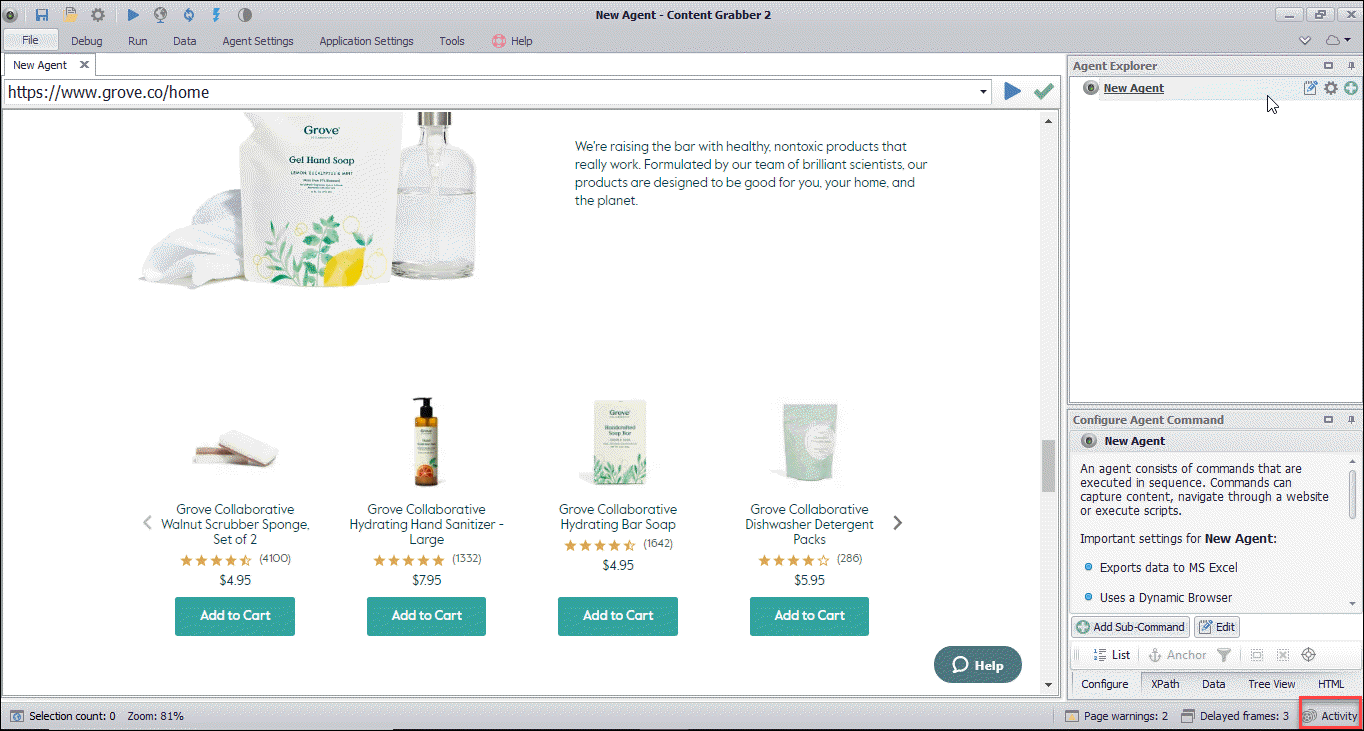
I can now open the browser activity screen to view all the requests that have been sent to the webserver. Sequentum Enterprise even tells me if any interesting JSON data has been returned from the server.
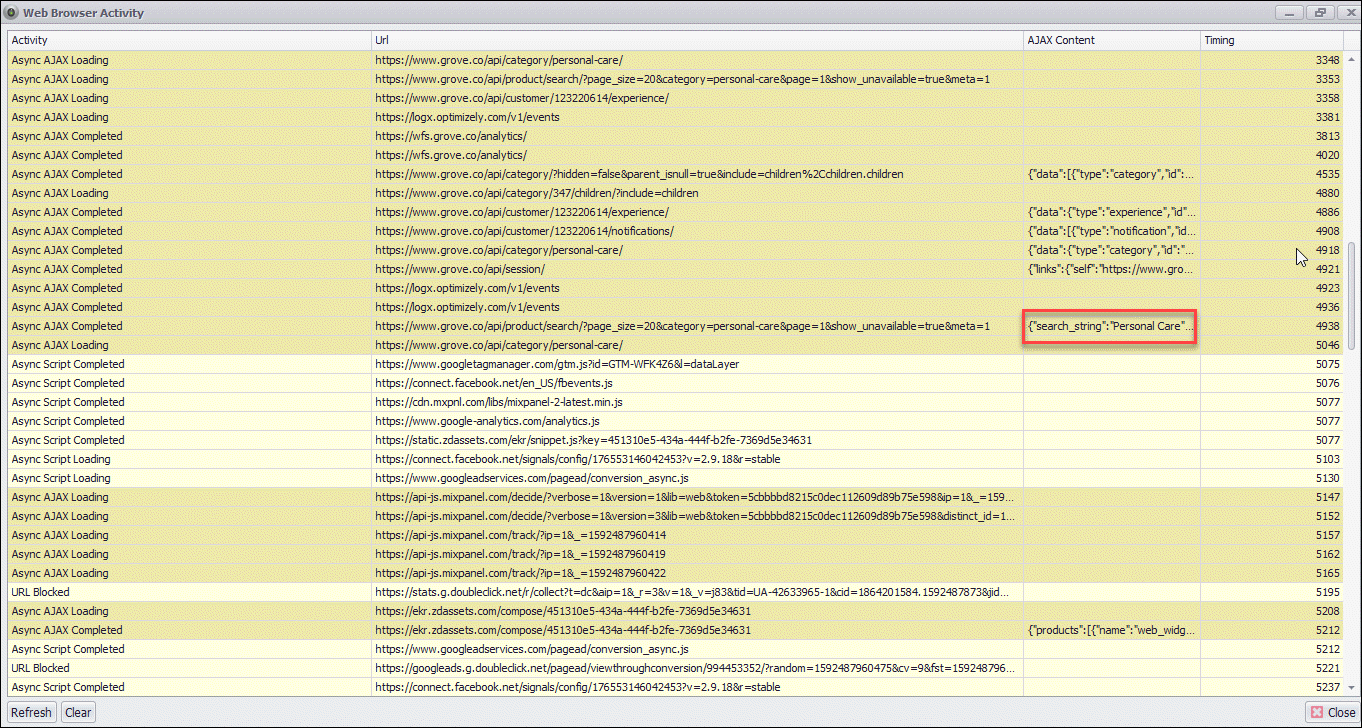
The Activity screen shows all web requests and makes it easy to find the ones returning JSON
I can view the JSON content to make sure it contains the data I’m interested in.
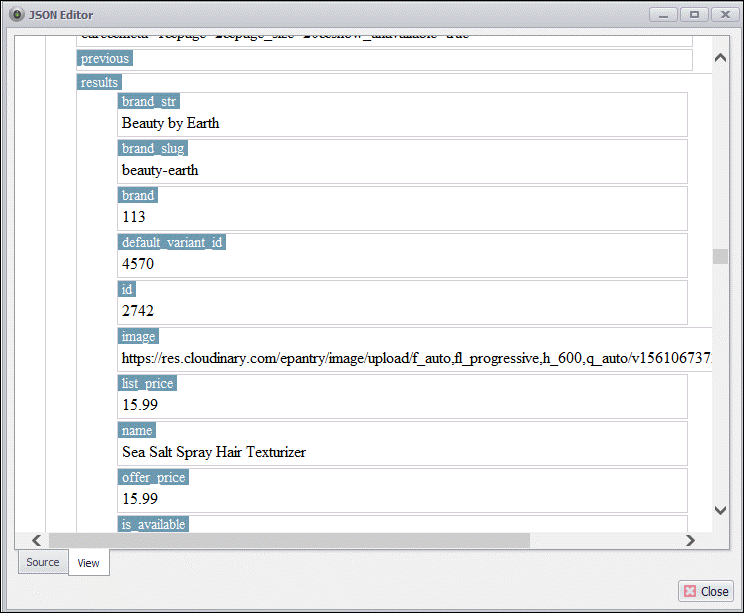
Double-clicking on the JSON field on the Activity screen brings up the JSON content
Now that I’m satisfied I’ve found the right Web API request, I’ll take a look at the request URL which looks like this:
If you look closely at the URL you’ll notice a URL parameter named pageSize. This parameter controls how many products are returned by the Web API request. I want to return all products in the category in a single request, so I’ll increase this number to a value that is high enough to return all products in the category. The URL now looks like this.
All I need to do now is load the URL into a JSON Parser in sequentum Enterprise, so make sure you change the Sequentum Enterprise browser from Dynamic Browser to JSON Parser. You can choose the Sequentum Enterprise browser type from the Agent Settings menu.
I get a nice view of the JSON data available, and creating the bot is an easy point and click process.
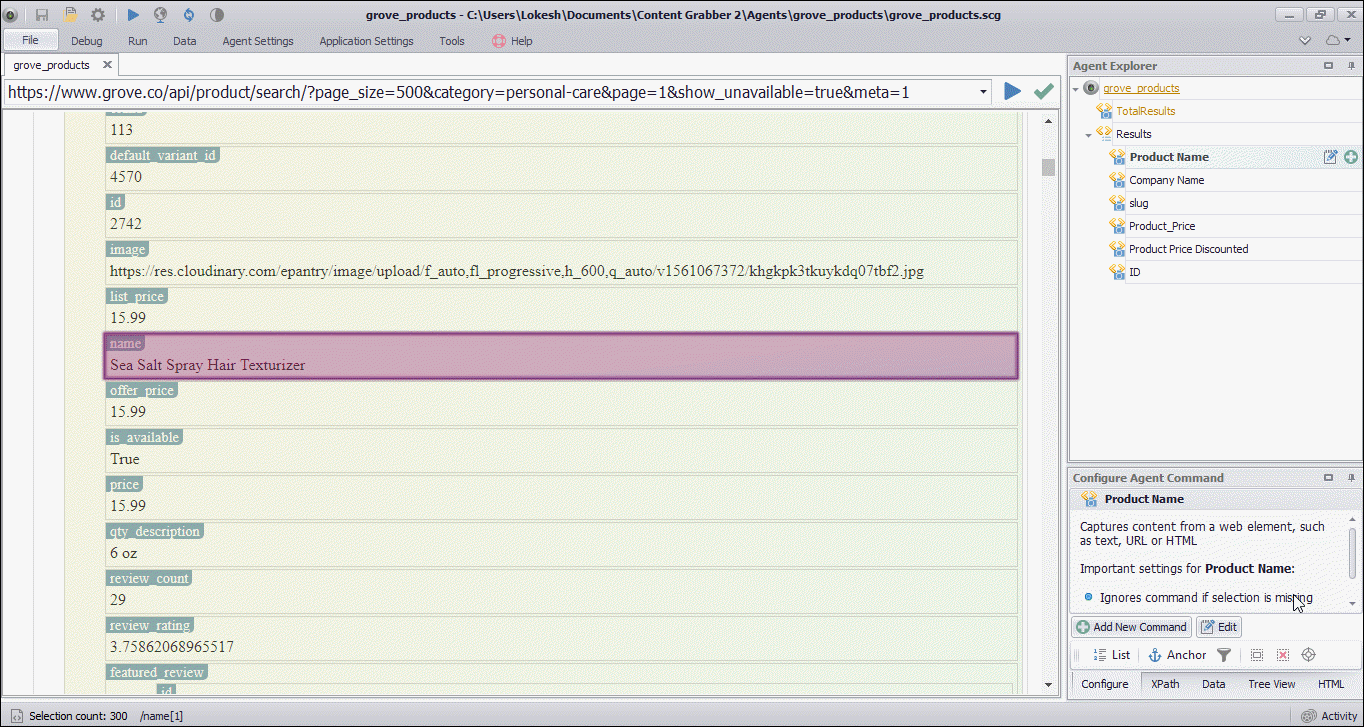
To create the Sequentum Enterprise bot, simply point and click on the data elements you want to extract
Performance
The bot I’ve created extracts 300 products in 10 seconds, and 5 seconds of that is used to initialize the agent, so the actual extraction has taken only a couple of seconds. This would easily have taken 10-20 times as long using a full-featured web browser.
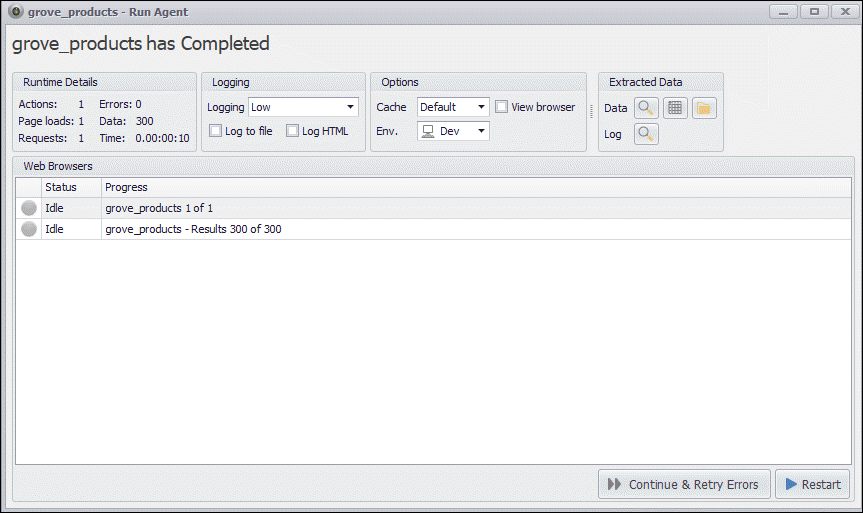
The bot has extracted 300 products in 10 seconds
The Extracted Data
Since I’m using Sequentum Enterprise, I can easily save my extracted data almost anywhere with the click of a button, including databases, CSV, Excel, XML, JSON and PDF. Here’s what the data looks like in Excel.
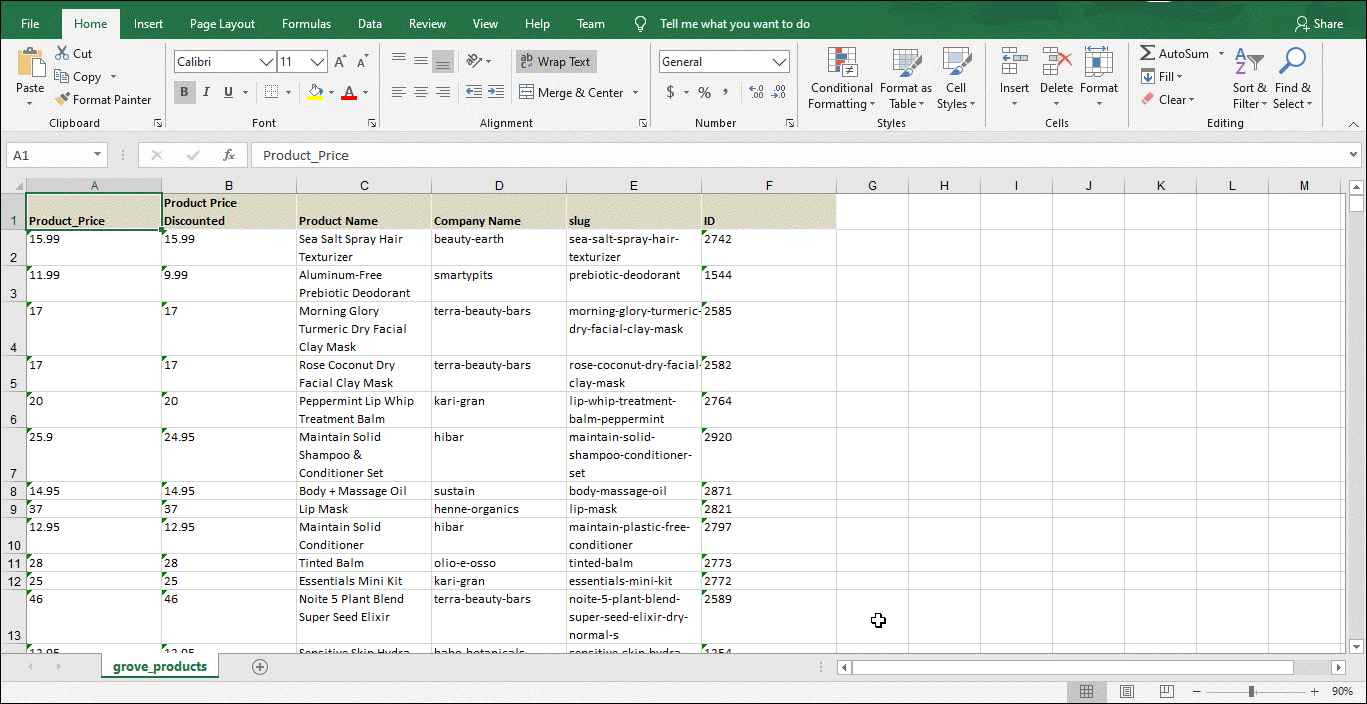
The extracted data in Excel format
Conclusion
Extracting data from a modern website can be a nightmare, but it doesn’t have to be. I’ve shown how you can hook up directly to a Web API and get rich data fast and reliably. You don’t even have to get your hands dirty with programming if you use the right web scraping tool.
If you have any questions, please use the comment section below or contact us here.