
Web Scraping on Modern Websites – Part 2
This article is the second part of my blog series Fast and Reliable Web Scraping on Modern Websites. If you have not already read my first article, I recommend you do so before you continue.
In my first article, I wrote about a technique to extract data from modern websites that load JSON data asynchronously from Web APIs. The example I used was a grocery website that uses simple Web API requests like this one:
These kinds of web requests are very easy to deal with because they are simple GET requests. In fact, you can load them directly into a web browser by simply putting the URL into the browser’s address bar. Unfortunately, it’s not always that easy. Sometimes you need to post data to the Web API and add specific headers to your web requests to get the Web API to respond properly.
In this article, I’ll show you how you can still use this awesome technique to extract data, even when you need to generate complex web requests to get data out of the Web API.
Generating Complex Web API Requests
Generating complex Web API requests is a two-step process. First, you need to detect and inspect the web requests the website is sending to the Web API, and then you need to use this information to generate your own web requests.
Detecting and inspecting web requests can be done in programs such as Fiddler, Web Browser developer tools, or dedicated web scraping tools such as Sequentum Enterprise. The process is similar to the process I went through in my first article, but this time I also need to look at the web request headers and any data being posted to the Web API.
An Example
I’ll use the grocery website shopwoodmans.com as an example of how to deal with complex Web API requests. This website is more advanced than the grocery website I used in my first article because it loads data asynchronously as you scroll down a page to view more products. Most high-end web scraping tools can deal with this scenario without the use of direct Web API requests, but it can be difficult, slow, and unreliable, so it’s a good website to showcase the advantage of using direct Web API requests.
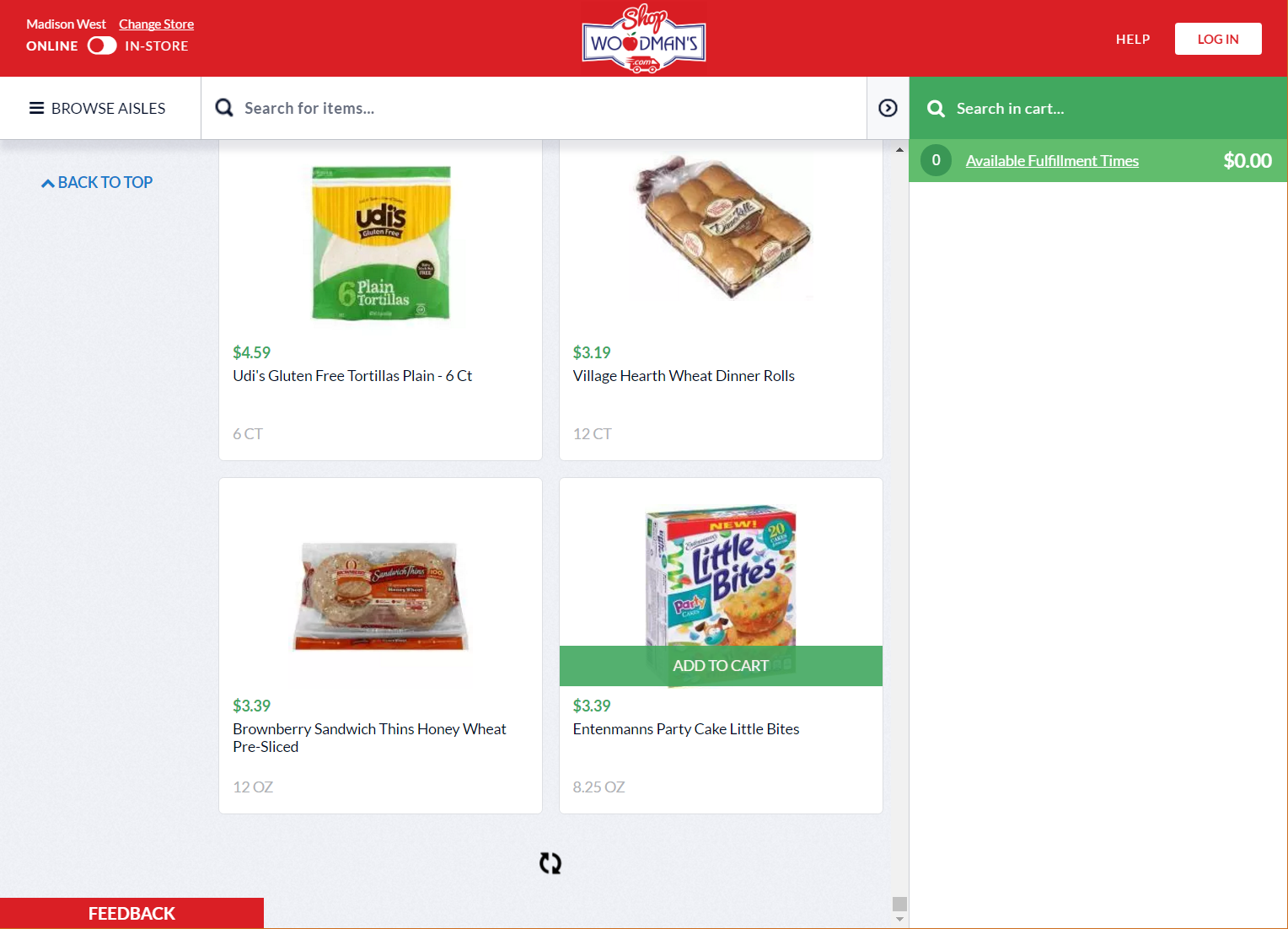
On this website products are loaded asynchronously as I scroll down the page
Like the example in my first article, I’ll use Sequentum Enterprise to inspect the web requests, because it has excellent tools to both inspect, generate, and test complex web requests.
First I’ll load the website into Sequentum Enterprise, and then scroll down the product list to trigger the Web API requests that loads more data.
I can now open the Browser Activity screen in Sequentum Enterprise to look for Web API requests of interest.
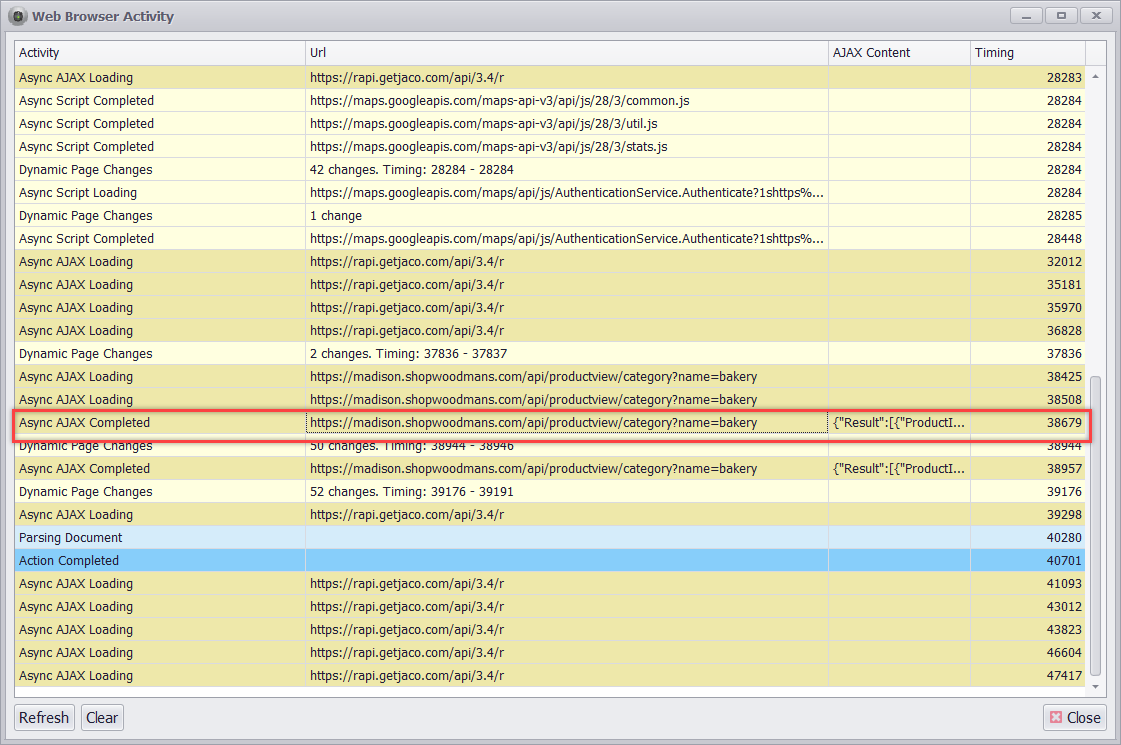
I’m looking for web requests that are returning JSON
After looking through the list of web requests, I’ve found the following request returns product data in JSON format.
https://madison.shopwoodmans.com/api/productview/category?name=bakery
I can double-click on the URL to open the Web Request editor. This editor allows me to view the entire Web Request with URL, headers, and post data.
Normally, I don’t like to send specific headers with my Web API requests, because they sometimes contain dynamic information that can be a bit difficult to generate, such as session IDs, so I’ll start by removing all the headers and test the request.
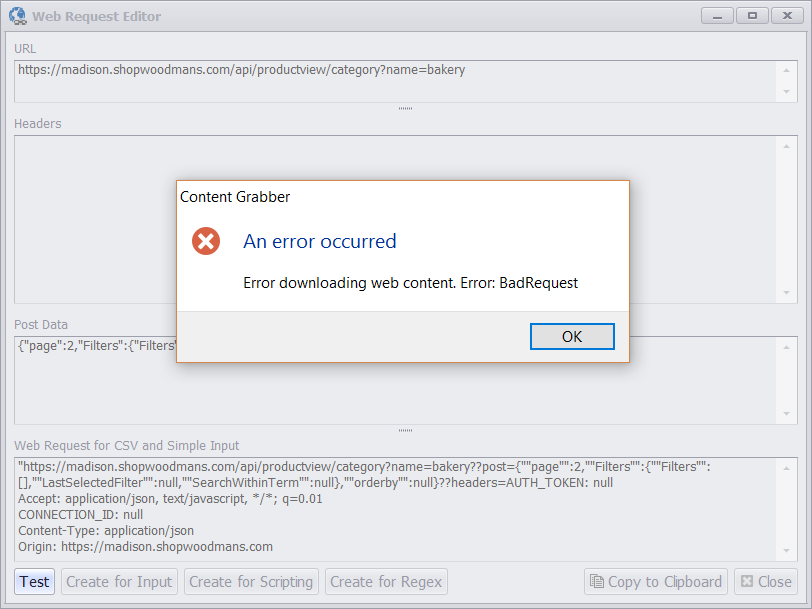
I’ve removed all the request headers, but when I test the request the Web API returns an error
I’m getting an error back from the Web API, so that means I need to add some headers, but not necessarily all the headers. After fiddling with the headers for a while, I’ve come up with the perfect set of headers that just includes the custom header “sourceStore” and the content type, and still gives me a correct response from the Web API.
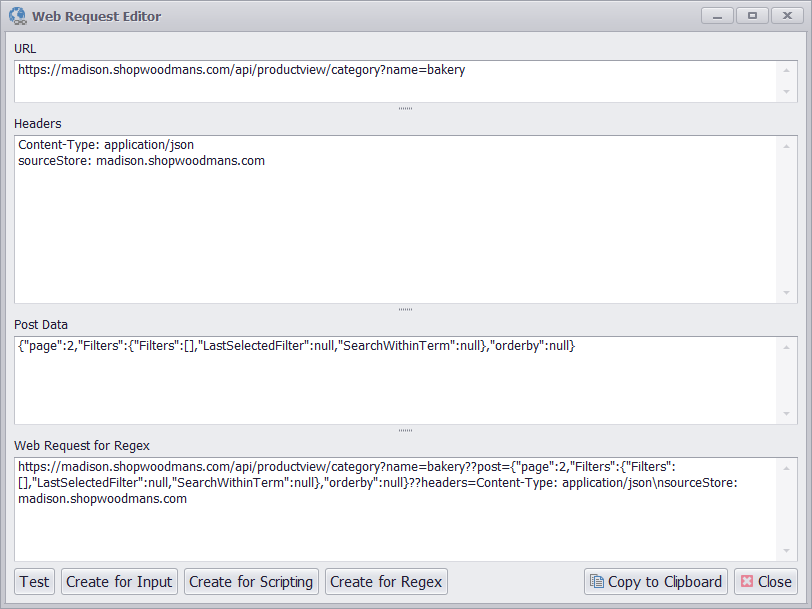
I’ve removed most of the headers from the request, and only kept the two that are required
I’ll now direct my attention to the post data. There’s no way to specify the number of products the Web API should return, so I need to get the data page-by-page by making multiple Web API requests while increasing the page number in the post data. In Sequentum Enterprise I can easily create a web scraping bot that does exactly that.
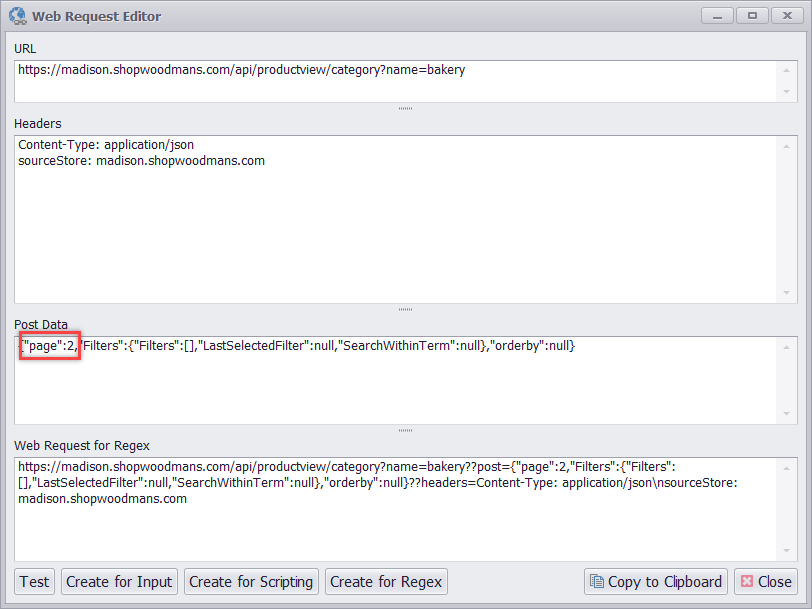
The post data has a parameter “page” that specifies the page of products the Web API returns
Sequentum Enterprise uses specially formatted URLs to add headers and post data to a web request. The Web Request editor generated the following Sequentum Enterprise URL.
https://madison.shopwoodmans.com/api/productview/category?name=bakery??post={“page”:2,”Filters”:{“Filters”:[],”LastSelectedFilter”:null,”SearchWithinTerm”:null},”orderby”:null}??headers=Accept: application/json, text/javascript, */*; q=0.01\nContent-Type: application/json\nsourceStore: madison.shopwoodmans.com
You can load this URL directly into Sequentum Enterprise as you would any other URL, and Sequentum Enterprise will automatically add the specified headers and post data.
Creating the Sequentum Enterprise Web Scraping Bot
I’ll create a Sequentum Enterprise web scraping bot that generates and loops through a number of web requests with increasing page numbers. I don’t know exactly how many pages of products are available on the website, so I’ll just generate enough requests to make sure I get to all the available pages. Once a web request returns no product data, I know there are no more pages available and I can exit the loop.
Here are the steps to create the web scraping bot in Sequentum Enterprise.
Step 1
Create a new agent in Sequentum Enterprise and edit the Agent command. Then use a Number Range data provider to provide start URLs for the agent. The numbers provided will be the page numbers in the web requests and I’ll generate a maximum of 1000 page numbers. I’m confident this number will be high enough to get all products from the product category I’m extracting.
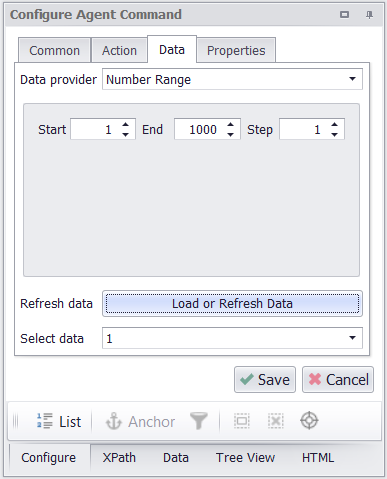
I’ll use a Number Range data provider to generate page numbers
The start URLs are now just numbers and not real URLs, so I’ll use a Transformation Expression to transform the numbers into real web request URLs. I’ll do that by using the web request I got from the Web Request editor, and just insert the page numbers into that request.
I could use a C# or VB.NET script to insert the page numbers into the web request, but to avoid any coding I’m using the Regular Expression editor to simply take the page number and return the web request with the page number inserted.
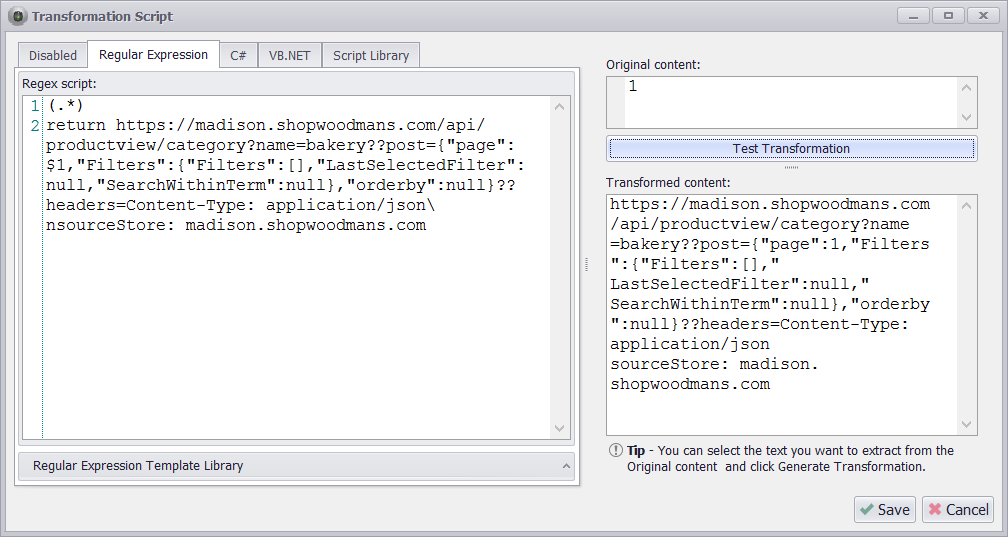
I’m not really using Regex here, but the Regex Editor is useful for taking the page number and inserting it into the start URL
Now that I’m providing the right web requests as start URLs, I can execute the agent command and load the JSON returned by the Web API. Make sure you configure the Agent command to use a JSON parser instead of a full featured web browser.
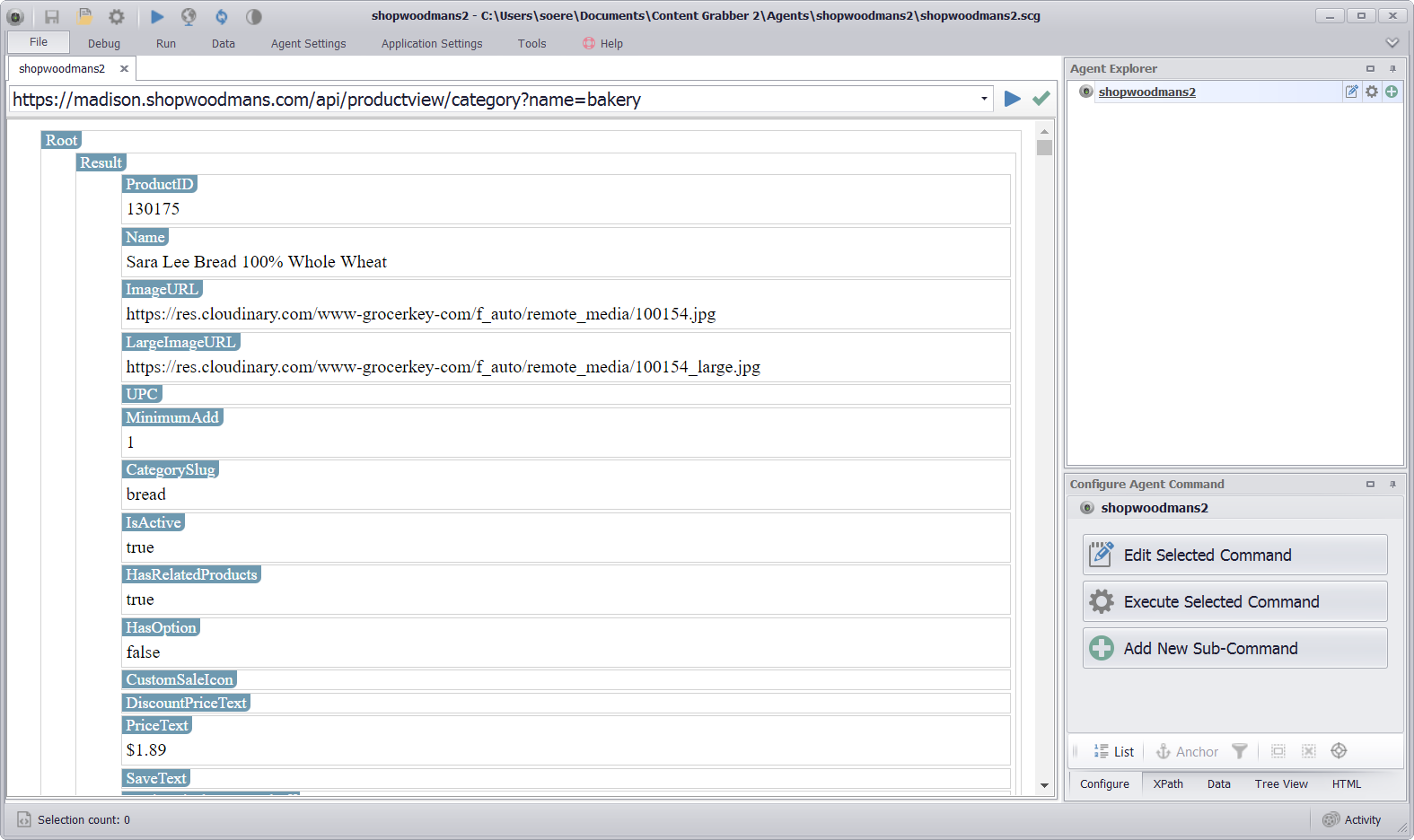
The Web API request for page one loaded in the Sequentum Enterprise JSON Parser
Step 2
Now that I have the JSON data loaded up into my JSON Parser, I can simply point and click to configure my bot to extract data from the JSON returned from the Web API. My agent commands now look like this.
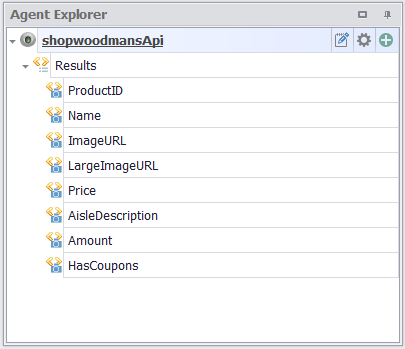
Just point-and-click on the JSON data elements you want your bot to extract and agent commands are added automatically
Step 3
As I’ve mentioned before, I don’t know exactly how many product pages are available, so I’ve configured the agent to just keep executing Web API requests with increasing page numbers up till a maximum of 1000. I want to make sure my web scraping bot stops when there are no more products available, so I’ll add an Exit command to my agent that exits the agent when a web request returns no data.
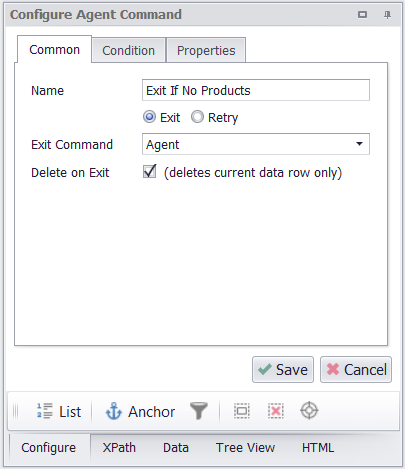
I’m adding an Exit command that will exit the agent when no more products are available
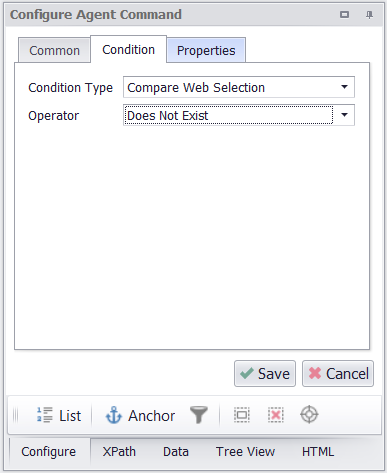
The Exit command selects all the products in the JSON data and exits if the selection doesn’t exist
My final agent now looks like this.
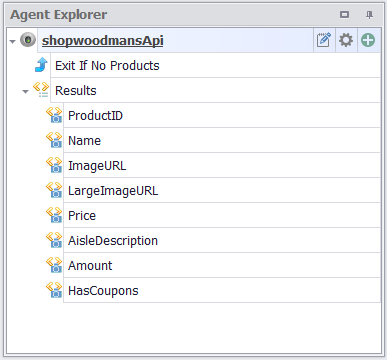
My final agent
Let’s Run the Web Scraping Bot
I can now run the web scraping bot and the 1363 products in the bakery category are extracted in 14 seconds.
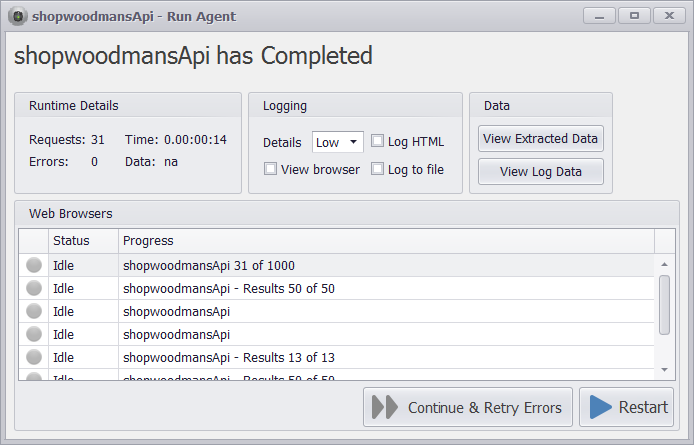
The agent extracts 1363 products in 14 seconds
Here’s how the extracted data looks in Excel.
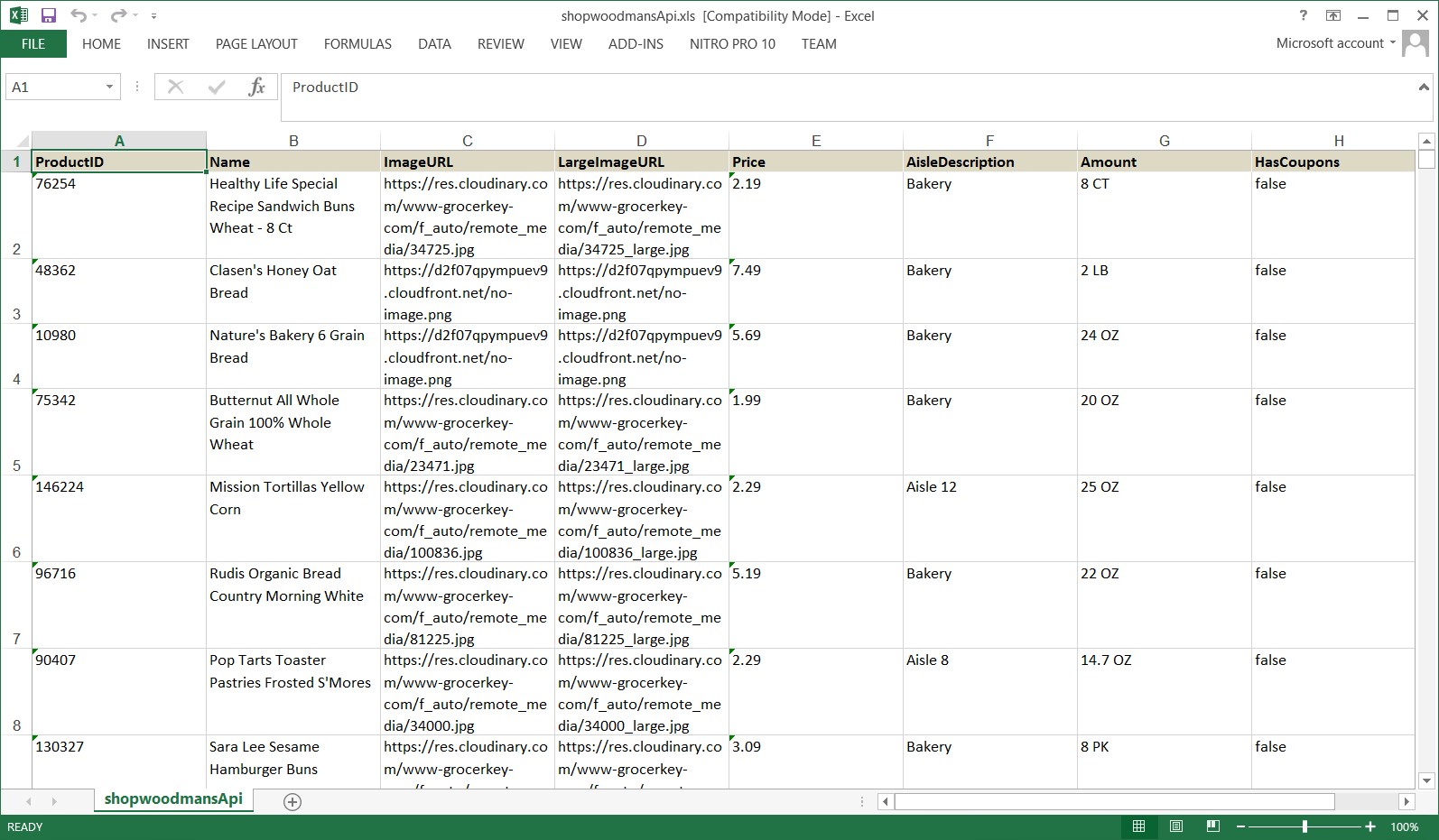
The extracted data in Excel format
I’ve also gone ahead and created a web scraping bot using the full featured web browser in Sequentum Enterprise. This bot scrolls down the web page to discover and extract more products. This bot takes 5 minutes and 18 seconds to extract the 1363 products in the Bakery category, so a massive time difference compared to the bot using direct API calls.
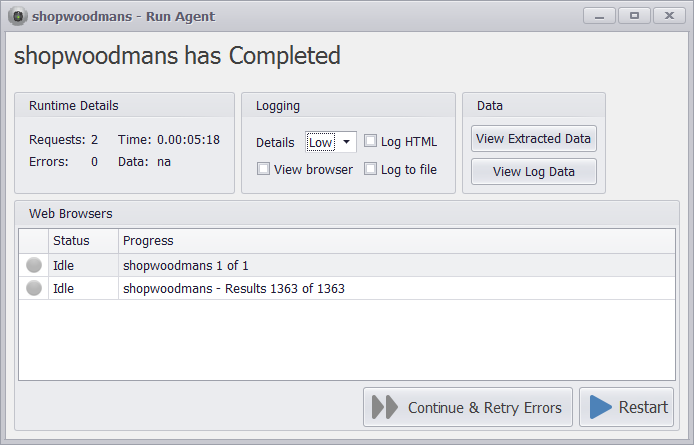
The agent using a full featured web browser is slow
Conclusion
I’ve shown how you can easily create web scraping bots to extract data from modern websites, even when the websites use complex communication with Web APIs.
I created two web scraping bots. One using direct Web API calls and one using a full featured web browser. The one using direct Web API calls was much faster than the one using the full featured web browser, but speed is not the only benefit of using direct Web API calls. Web browsers are very complex programs, and loading a modern website into a web browser is an extremely complex process from a technical point of view. Comparably, accessing a Web API is a very simple process and the chance of something going wrong is minimal compared to using a web browser, so you’re getting both great speed and great reliability.
In the next blog post in this series, I’ll show you how to deal with road blocks, such as cross site forgery tokens (CSRF), which can easily put a stop to the fun of scraping data directly from Web APIs. I’ll be dealing with the www.budget.com website which is part of the AVIS car rental group. All the AVIS owned websites use the same Web API, so you can use the exact same technique for all of them, but CSRF tokens are very common, so this will be an excellent guide for all websites using CSRF tokens.