
Use Input Subsets and Multiple Sessions for Parallel Processing of Data
Input subsets involve breaking down large datasets into smaller, manageable portions for parallel processing. This approach is particularly beneficial when dealing with substantial data volumes, enabling task distribution across multiple Subsets or nodes within a cluster. By segmenting the workload into subsets, the overall processing time can significantly be reduced. The segmentation of workloads into subsets significantly reduces overall processing time and allows the execution of parallel sessions based on specific requirements and site sensitivity.
Auto processing Inputs Using Input Subsets
When it comes to auto processing inputs using input subsets, following three methods can be employed:
Start Job Using ACC :
Initiates an agent job run, keeping track of all runs started by the job.
Multiple jobs for the same agent cannot run simultaneously.
It's often used together with performance sessions.
For more information please refer to Start Job Using ACC Documentation
Start Agent Using ACC :
Sequentum Enterprise divides a large task by breaking list entries into subsets, allowing each agent instance to work on one of those subsets.
For more information please refer to Start Agent Using ACC Documentation
Start Agent Using Web Request :
Run the agent by placing the start agent request URL into any web browser containing the start agent API URL with the agent name path.
Initiating parallel processing of input subsets
We can optimize the execution by concurrently initiating input subsets. This involves dividing inputs into subsets and running each subset on a different server. This approach not only reduces the agent's processing time but also prevents the risk of data loss caused by website blocking.
To illustrate, consider the case of an organization utilizing a website, where extended runtime and frequent blocking issues were observed. To address this, the inputs are divided into subsets, with each subset processed on a separate server, resulting in reduced runtime and lesser impact of blocking issues, particularly given the website's sensitivity and use of Akamai cookies.
For Example : If a user is trying to extract data from a website which requires login and he wants to use different set of logins to extract data at the same time, In such a case, the user can put all the logins into a file and use Input Subsets to either process them together for parallel processing of subsets or they can use it for running one after the other.
Another option would be they can use Multiple Sessions and Input Parameters to run separate logins all at once.
Steps:
Take a csv input file in the "input" folder with login credentials and use it in the input parameter.
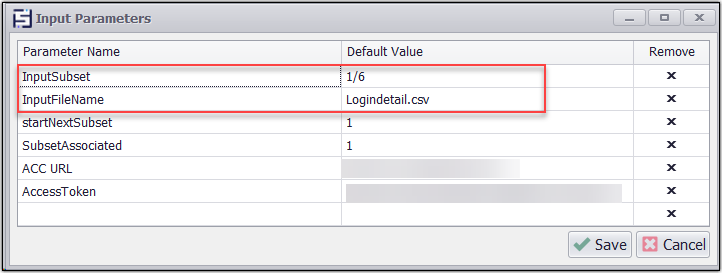
In the above screenshot, the value of Input Subset is indicated as 1/6, which denotes that the inputs from the Logindetail.csv file are divided into two subsets.Now add a Data List command and write the script as shown below which will read the values of the input CSV file and pick the values as per session and subset.
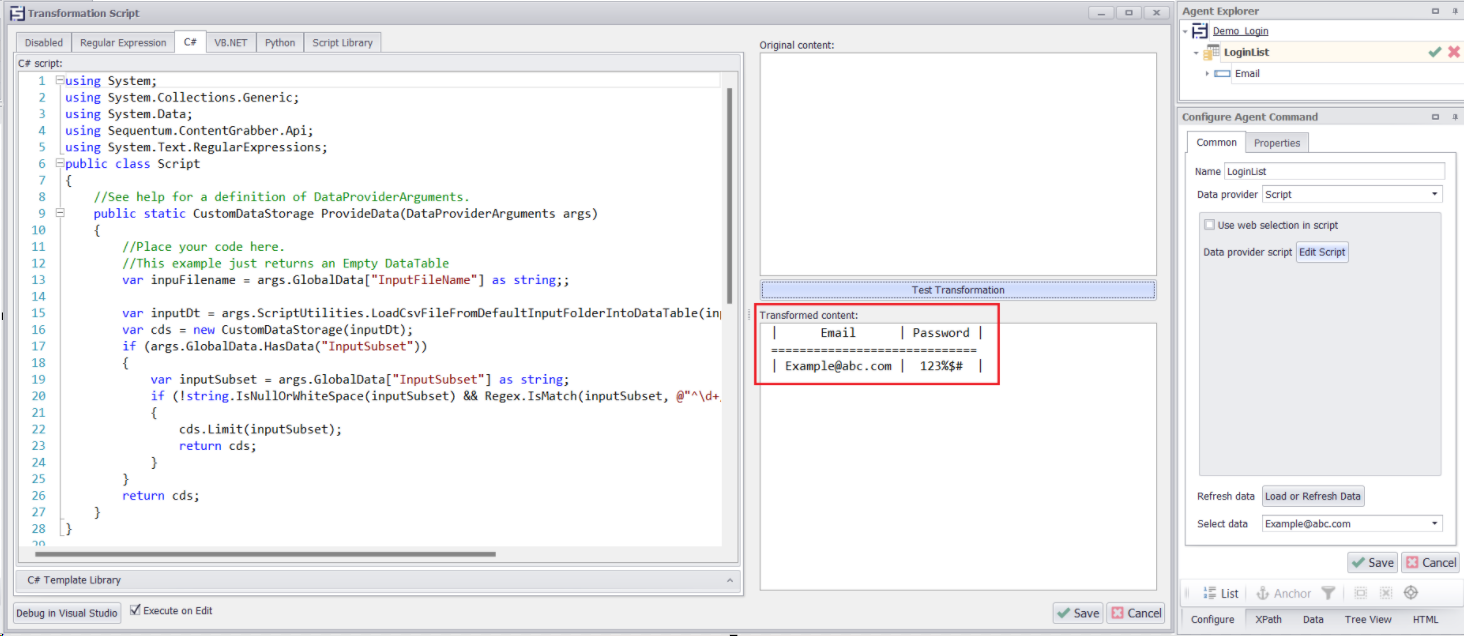
Input Subset Script Implementation
In the above screenshot, we've utilized a script within the data list command to divide the inputs according to the specified input subsets. Our input file contains six login details, and we're using the 1/6 notation to assign one input per subset.
using System;
using System.Collections.Generic;
using System.Data;
using Sequentum.ContentGrabber.Api;
using System.Text.RegularExpressions;
public class Script
{
//See help for a definition of DataProviderArguments.
public static CustomDataStorage ProvideData(DataProviderArguments args)
{
//This example just returns an Empty DataTable
var inpuFilename = args.GlobalData["InputFileName"] as string;
var inputDt = args.ScriptUtilities.LoadCsvFileFromDefaultInputFolderIntoDataTable(inpuFilename, true);
var cds = new CustomDataStorage(inputDt);
if (args.GlobalData.HasData("InputSubset"))
{
var inputSubset = args.GlobalData["InputSubset"] as string;
if (!string.IsNullOrWhiteSpace(inputSubset) && Regex.IsMatch(inputSubset, @"^\d+/\d+$", RegexOptions.None))
{
cds.Limit(inputSubset);
return cds;
}
}
return cds;
}
}Automating Web Scraping Subsets with StartAgent and StartJob API Methods
Code Example - C#
using System;
using System.IO;
using Sequentum.ContentGrabber.Api;
using Sequentum.ContentGrabber.Commands;
using System.Threading;
public class Script
{
public static bool ExportData(DataExportTargetArguments args)
{
var startSubset = args.GlobalData["startNextSubset"] as string;
if (startSubset == "1")
startNextSubset(args, startSubset);
return true;
}
public static string startNextSubset(DataExportTargetArguments args, string startSubset)
{
var access_token = <Access Token>;
var agent_id = args.Agent.AgentId.ToString();
var acc_url = args.GlobalData["ACC_URL"] as string;//"http://acc2.sequentum.com ";
var InputSubset = args.GlobalData["InputSubset"] as string; //- 1/10
var InputFileName = args.GlobalData["InputFileName"] as string;
var str_ScheduleAssociated = args.GlobalData["SubsetAssociated"] as string;//e.g. 1, 2, 3 only integer values
int ScheduleAssociated = Convert.ToInt16(str_ScheduleAssociated);
if (InputSubset.Contains("/"))
{
int session_existing_number = Convert.ToInt32(InputSubset.Split('/')[0]);
int session_total_number = Convert.ToInt32(InputSubset.Split('/')[1]);
int next_session_id = session_existing_number + ScheduleAssociated;
var session_id = string.Format("{0}_{1}", next_session_id.ToString(), session_total_number.ToString());
if (next_session_id <= session_total_number)
{
var headers = "Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8";
headers += "\nUpgrade-Insecure-Requests: 1";
headers += "\nContent-Type: application/json";
headers += "\nAuthorization: Bearer " + access_token;
var postContents = @"{""sessionId"":""" + session_id + @""", ""logLevel"":1, ""isProductionRun"":true, ""runMethod"": ""Restart"", ""useMultipleSessions"": true";
postContents += @",""inputParameters"":""{\""InputFileName\"":\""" + InputFileName + @"\""";
postContents += @",\""SubsetAssociated\"":\""" + str_ScheduleAssociated + @"\""";
postContents += @",\""startNextSubset\"":\""" + startSubset + @"\""";
postContents += @",\""InputSubset\"":\""" + string.Format("{0}/{1}", next_session_id.ToString(), session_total_number.ToString()) + @"\""";
postContents += @"}""}";
var startAgentOnClusterAPI = string.Format("{0}/api/agent/{1}/cluster/start", acc_url, agent_id);
args.WriteDebug(postContents, true, DebugMessageType.Information);
args.WriteDebug(startAgentOnClusterAPI, true, DebugMessageType.Information);
var result = args.ScriptUtilities.PostDataWithStatus(startAgentOnClusterAPI, System.Text.Encoding.UTF8.GetBytes(postContents), headers, 60000, false);
}
}
return "done";
}
}Using Input Subsets with StartAgent API
Divide the Dataset
Break down the large dataset into smaller, manageable subsets based on the specific task requirements.
Create API Requests for Each Subset
Generate individual API requests for each subset, ensuring inclusion of necessary parameters viz. agent name and authentication key, which further gets automated, and the subsets run one after the other automatically or will run parallelly as per the requirement and sensitivity of the website.
Initiate StartAgent API for Each Subset
Use the StartAgent API to concurrently initiate task execution for each subset, leveraging parallel processing capabilities for faster and more efficient data processing.
Monitor and Manage Execution
Implement mechanisms to monitor the next subset's progress, manage execution flow, handle errors, and ensure proper synchronization.
Using Start Job API and Start Agent API with Sequentm Enterprise
Step 1: Provide Input Parameter
Provide input parameters to the agent, as shown in the provided screenshot.
Note : You can get Access Token (API Key) from ACC by simply just logging in with the ACC URL, After that Login > Organizations > Public Encryption Key. For more details regarding authentication Access Token, please see this article. API Access | Start-agent-on-cluster
Step 2: Write Code in Data Provider Script
Write code in the data provider script to retrieve input data based on the provided subsets in the input parameter. For instance, if we have a total of 1000 inputs in the input file and Input Subset is set as one by one (1/1) for all input values, all the data will be visible in the input as depicted in the screenshot below.
var cds = new CustomDataStorage(finalDT);
if (args.GlobalData.HasData("InputSubset"))
{
var inputSubset = args.GlobalData["InputSubset"] as string;
if (!string.IsNullOrWhiteSpace(inputSubset) && Regex.IsMatch(inputSubset, @"^\d+/\d+$", RegexOptions.None))
{
cds.Limit(inputSubset);
return cds;
}
}
return cds;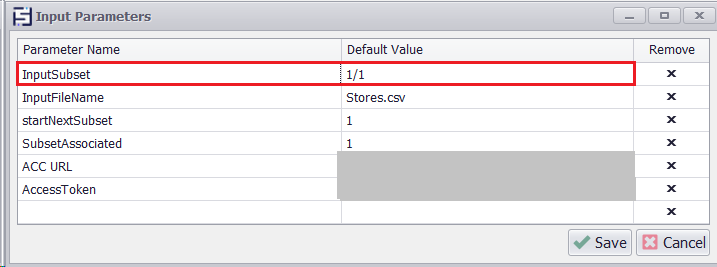
Input Subset Provided as 1/1 to get all inputs
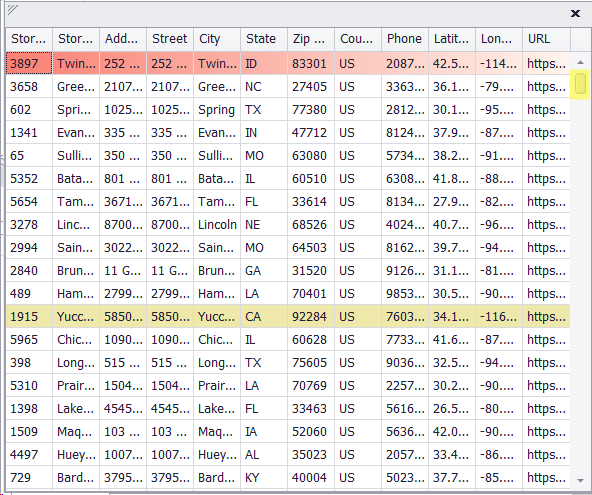
Retrieving Input Data with Input Subset (1/1)
Step 3: Dividing Input Data into Subsets
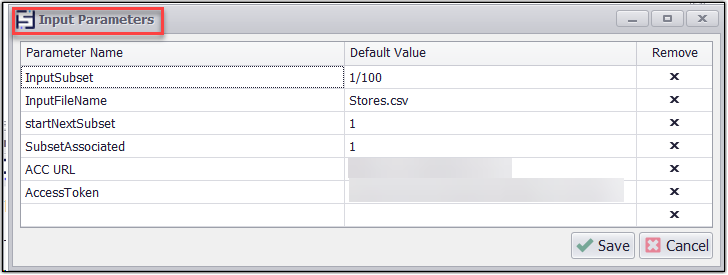
In the input parameter , We have added Input Subset as 1/100 to divide the input values into subsets. You will notice that the input data is now divided into subsets.
While utilizing Input Subsets as 1/100 and dividing the 1000 inputs from the input file into 100 subsets, resulting in 10 inputs per subset as shown below:
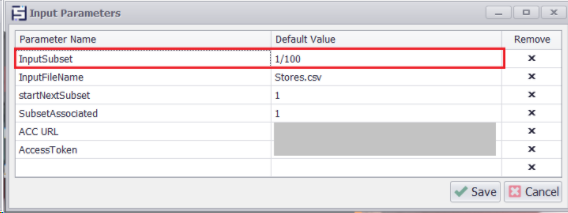
Dividing Input Data into Subsets (1/100)
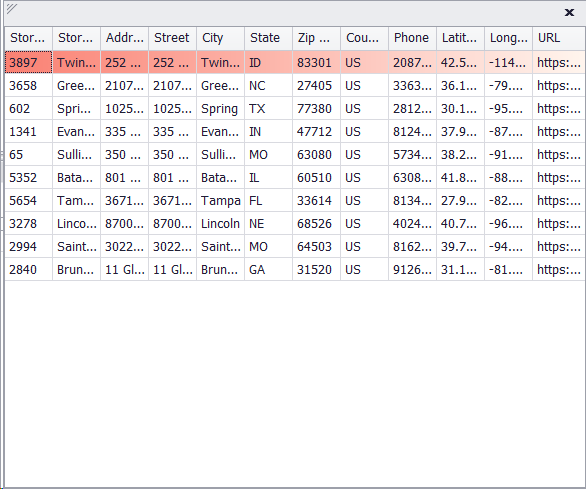
Input Data divided into subsets (1/100)
Step 4: Run the Agent
As per step 3, we have taken the input subset as 1/100 and now run the agent and you will see that the subsets will start running and the data will get delivered in sections and per subset, 100 inputs will be executed.
using System;
using System.IO;
using Sequentum.ContentGrabber.Api;
using Sequentum.ContentGrabber.Commands;
using System.Threading;
public class Script
{
public static bool ExportData(DataExportTargetArguments args)
{
var startSubset = args.GlobalData["startNextSubset"] as string;
if (startSubset == "1")
startNextSubset(args, startSubset);
return true;
}
public static string startNextSubset(DataExportTargetArguments args, string startSubset)
{
var access_token = <Access Token>;
var agent_id = args.Agent.AgentId.ToString();
var acc_url = args.GlobalData["ACC_URL"] as string;//"http://acc2.sequentum.com ";
var InputSubset = args.GlobalData["InputSubset"] as string; //- 1/10
var InputFileName = args.GlobalData["InputFileName"] as string;
var str_ScheduleAssociated = args.GlobalData["SubsetAssociated"] as string;//e.g. 1, 2, 3 only integer values
int ScheduleAssociated = Convert.ToInt16(str_ScheduleAssociated);
if (InputSubset.Contains("/"))
{
int session_existing_number = Convert.ToInt32(InputSubset.Split('/')[0]);
int session_total_number = Convert.ToInt32(InputSubset.Split('/')[1]);
int next_session_id = session_existing_number + ScheduleAssociated;
var session_id = string.Format("{0}_{1}", next_session_id.ToString(), session_total_number.ToString());
if (next_session_id <= session_total_number)
{
var headers = "Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8";
headers += "\nUpgrade-Insecure-Requests: 1";
headers += "\nContent-Type: application/json";
headers += "\nAuthorization: Bearer " + access_token;
var postContents = @"{""sessionId"":""" + session_id + @""", ""logLevel"":1, ""isProductionRun"":true, ""runMethod"": ""Restart"", ""useMultipleSessions"": true";
postContents += @",""inputParameters"":""{\""InputFileName\"":\""" + InputFileName + @"\""";
postContents += @",\""SubsetAssociated\"":\""" + str_ScheduleAssociated + @"\""";
postContents += @",\""startNextSubset\"":\""" + startSubset + @"\""";
postContents += @",\""InputSubset\"":\""" + string.Format("{0}/{1}", next_session_id.ToString(), session_total_number.ToString()) + @"\""";
postContents += @"}""}";
var startAgentOnClusterAPI = string.Format("{0}/api/agent/{1}/cluster/start", acc_url, agent_id);
args.WriteDebug(postContents, true, DebugMessageType.Information);
args.WriteDebug(startAgentOnClusterAPI, true, DebugMessageType.Information);
var result = args.ScriptUtilities.PostDataWithStatus(startAgentOnClusterAPI, System.Text.Encoding.UTF8.GetBytes(postContents), headers, 60000, false);
}
}
return "done";
}
}
Conclusion
In conclusion, leveraging input subsets and the Start Agent API provides a scalable and efficient approach for processing large datasets. By breaking down tasks into manageable portions and capitalizing on parallel processing capabilities, organizations can optimize their data workflows, enhancing efficiency and reducing processing times. The provided example API request serves as a practical illustration of implementing these concepts in real-world scenarios.