
Removing Duplicate Data
Duplicate data checks can be used to remove duplicate data. There are many ways to incorporate duplicate checks into an agent. The agent could check an external database to see if extracted data already exists, or it could check its own internal database. If an agent is configured to keep previously extracted data, it could check that data to see if the extracted data already exists there.
Use a Remove Duplicate command for simple removal of duplicates. For more complex ways of checking for duplicates, the task is best performed by a script. Sequentum Enterprise contains a default script that can be used for basic duplicate checks. To use the default duplicate script, add an Execute Script command and set the script type to Exit on Duplicate Data. This script tries to match data extracted in the current container command with existing data in the internal database. If it finds a match, it deletes the data it has extracted from the current container command and exits the container command.
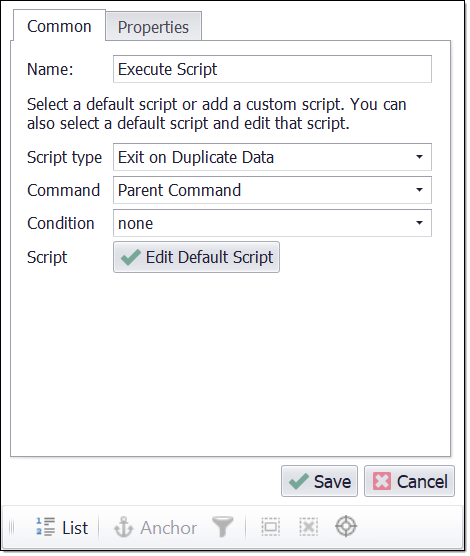
Default duplicate script
The position of the duplicate script is important. The script will only try and match data that has already been extracted in the current container command, so data extracted by capture commands that are positioned after the script command will not be used. For example, if a container command has three capture commands that extract Product ID, Product Name and Product Description, and the duplicate check should be done on the Product ID only, then the duplicate script should be positioned after the capture command that extracts the Product ID, but before the capture commands that extract Product Name and Product Description. If the duplicate check should be done on all the data extracted in the container command, then the duplicate script should be positioned last in the container.
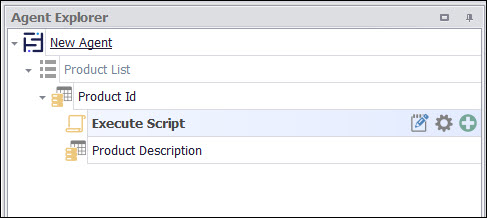
Duplicate check on Product ID and Product Name.
The default duplicate script tries to match extracted data with all existing data in the internal database. If the agent is configured to keep previously extracted data in the internal database, the duplicate check will be done on all data extracted in the current agent run and all data extracted in previous agent runs. If the agent is configured to delete old data, the duplicate check will only be done on data extracted in the current agent run.
Removing duplicate rows
There is also a way to remove duplicate rows across sessions. Suppose, you have multiple sessions running of an agent and you want agent to remove all duplicate rows from the exported data based on a certain key. This option is available under "Validation Rules" of Data section of the Sequentum Enterprise. For more information you can follow the link