
Using Glynt with Sequentum Enterprise
GLYNT makes data extraction from complicated documents easy. A powerful AI system and a simple, no-code user experience. Anyone can use GLYNT. This is why GLYNT integrates so well with Sequentum.
Before we use GLYNT to extract data from documents you may need to train a model using some training set of files similar to the ones you intend to extract data from. Once you establish your training sets, we can use the GLYNT API to interface with your GLYNT models.
While doing so, take note of the Datapool id, which you can find in the URL. Your URL will look like this:
https://ui.glynt.ai/data-pools/######/review/zvh8k1/extraction/7xwzF1
The string after data-pools in the URL is the Datapool id you should save this in your agent as a calculated value or input parameter.
Retrieving an API Access Token
To use GLYNT with Sequentum Enterprise you first need to obtain a API access token. You can use the web request editor to make a post request containing your username and password. This token expires every 12 hours. You will need this any time you interact with the API.
"https://api.glynt.ai/v6/auth/get-token/??headers=content-type: application/json??post={""username"":""<USERNAME>"",""password"":""<PASSWORD>""}"
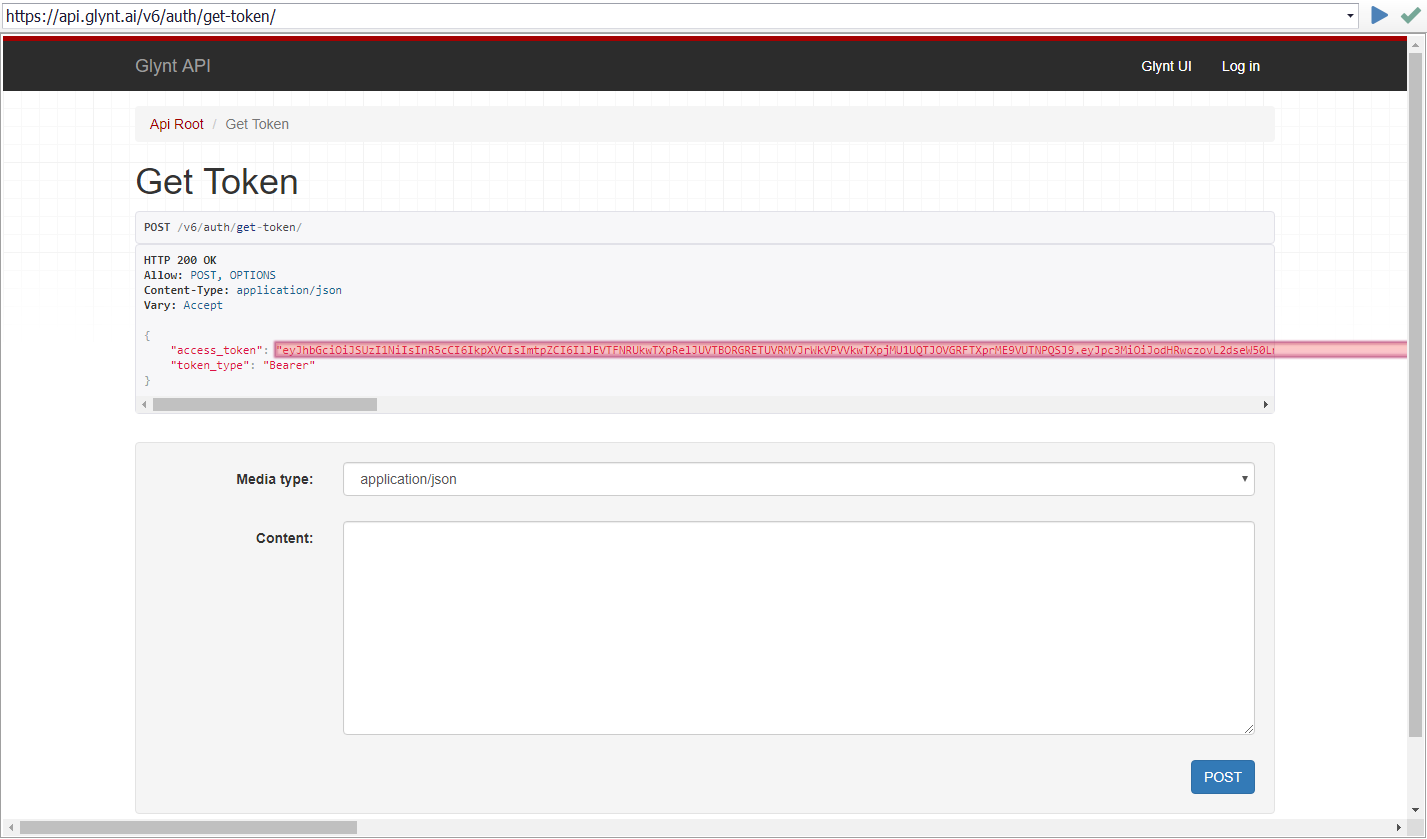
Once you have the access token, you'll need to save it as "token".
Creating a Document for Extraction
Any file you want to upload to GLYNT via the API, you'll have to convert to Base64, which you can do with a script. You should save this file as "file64" for later use.
To upload a document to GLYNT you will need to make a Create Document call to the API.
To do so, you should create a calculated value and paste in this value, editing the JSON values as you see fit:
https://api.glynt.ai/v6/data-pools/{$pool}/documents/??headers=Authorization: Bearer {$token}\ncontent-type: application/json??post={"label":"sample_doc_name","tags":["sample_tag"],"content_type":"application/pdf","content":"{$file64}"}
If you're token or converted file variables are not named "pool", "token" and "file64" you'll have to change that in the URL as well.
Create a Navigate URL command, selecting the aforementioned calculated value as the input. You'll have to transform the input with Regex transformation to insert the token and Base64 file.
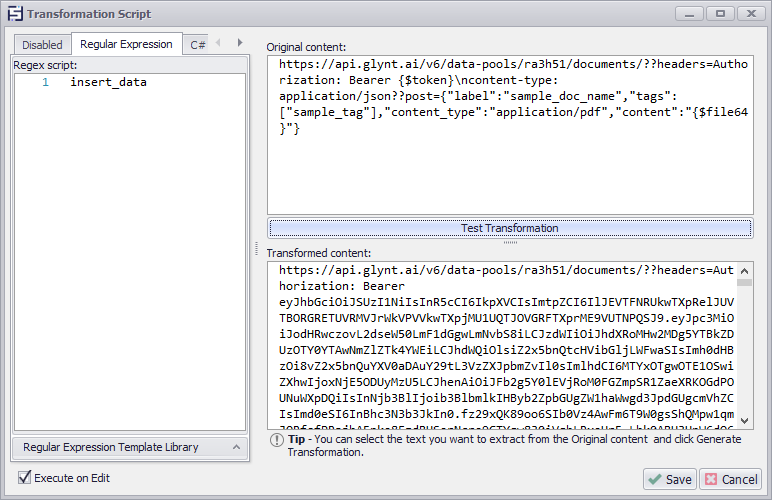
After successfully making that call, you should see this page:
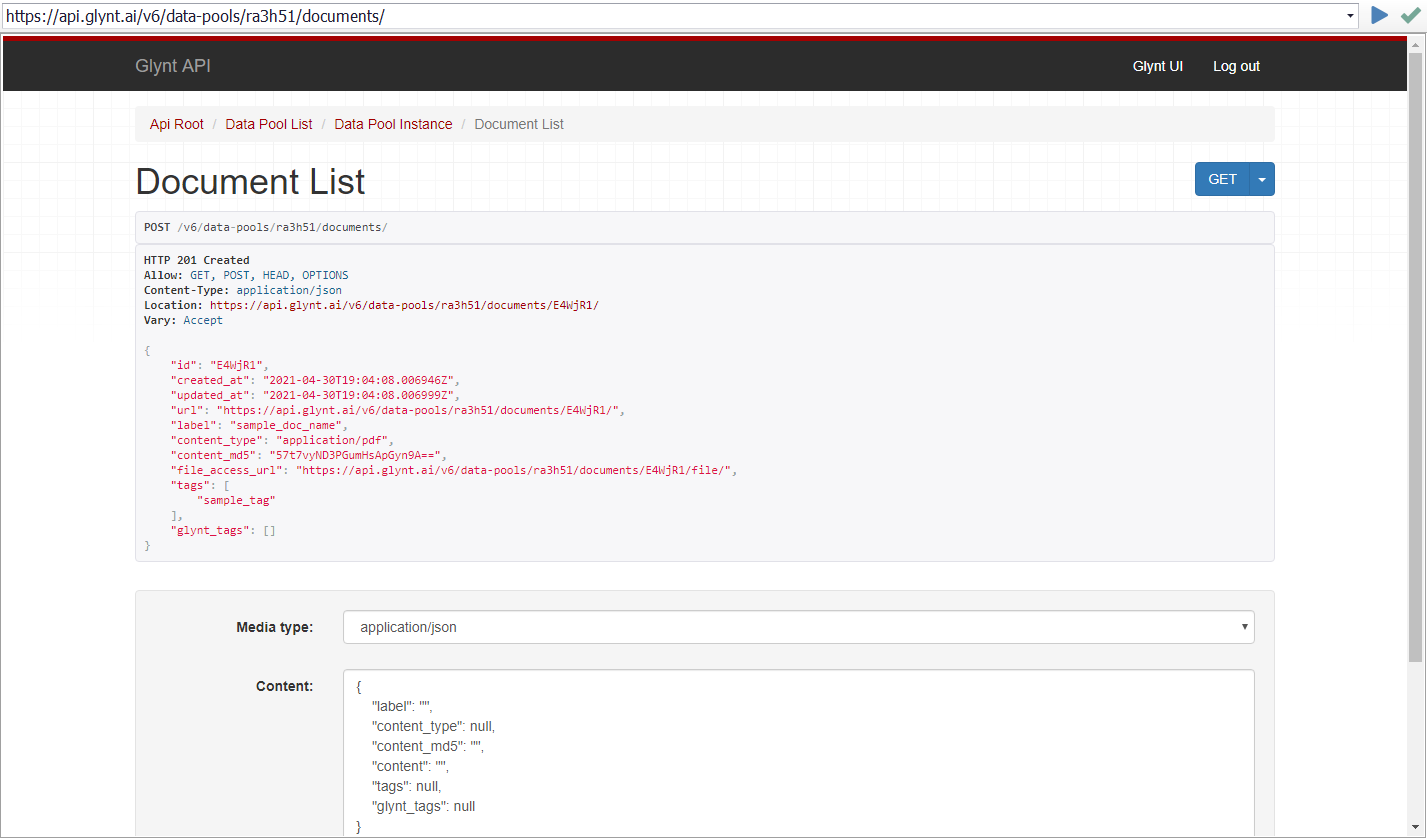
Extracting Data From a Document
Now that you've created a document you can extract data from it using a trained model. You should save the document id as you will need that to create an extraction. If you want to specify the model then you need to fetch the list of training sets and find the training set ID. You can make that call the same way you created a document with the web request below.
Retrieve Training Sets:
https://api.glynt.ai/v6/data-pools/{$pool}/training-sets/??headers=Authorization: Bearer {$token}
Once you have your training set, you can create an extraction using the id for the training set(model) and document.
Create an Extraction:
https://api.glynt.ai/v6/data-pools/{$pool}/extractions/??headers=Authorization: Bearer {$token}\ncontent-type: application/json??post={"training_set":"{$model}","document":"{$docID}"}
After successfully creating an extraction you will be returned an id for the extraction. You then use this to retrieve the extraction:
https://api.glynt.ai/v6/data-pools/{$pool)/extractions/{$extractID}/??headers=Authorization: Bearer {$token}
The response will contain a JSON object with the results of the extraction that looks like this:
"results": {
"Billing_Month": {
"content": "November 2018",
"tokens": [
{
"content": "November",
"page": 1,
"bbox": [
{"x": 1410, "y": 55},
{"x": 1644, "y": 55},
{"x": 1644, "y": 92},
{"x": 1410, "y": 92}
],
},
{
"content": "2018",
"page": 1,
"bbox": [
{"x": 1650, "y": 55},
{"x": 1720, "y": 55},
{"x": 1720, "y": 92},
{"x": 1650, "y": 92}
],
}
],
"tags": ["field_tags"],
"glynt_tags": ["field_glynt_tags"]
}
}
To extract this data you'll want to have Sequentum Desktop parse the JSON data.