
Crawling a Website
A Sequentum Enterprise agent normally follows a specified path through a website when extracting content. This is much faster than crawling an entire website to look for the content, because page loads are the main performance bottleneck when extracting data, and crawling an entire website will normally result in many more page loads than following a specified path through the website.
Sometimes it may not be possible to specify a fixed path through a website, since you may not know exactly where to find the content that you want to extract. For example, you may want to extract all email addresses on a website, but the email addresses could be located anywhere on the website, so the only option is the crawl the entire website and look for email addresses to extract.
Sequentum Enterprise has a built-in web crawling feature to navigate through every link on a web page. To crawl through every link on a page, click on add command and add a Crawl Website command.
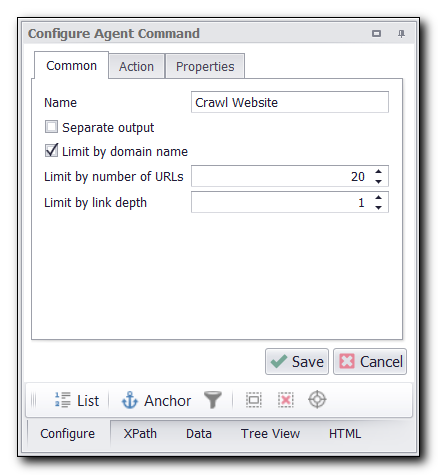
Default Web Crawler Command
Limit by number of URLs - Maximum number of URLs that the command will crawl on the main page.
Limit by link depth - Maximum number of sub-URLs that the command will crawl.