
Finding the optimal extraction approach to significantly reduce page requests
Often times you find that the websites from which you want to extract the data are large, yet you want the tasks to be completed quickly using the least resources. For example, servers that are to run the agents, proxies that are to bypass the blocking, with the least data errors too, plus you also don't want to burden those websites.
However, the less optimal extraction approach may end up being a very time-consuming, resources-intensive, errors-prone extraction process. It's often too late to find out that it's the wrong approach after a day's extraction.
In this post, I will show you how to identify an optimal approach and extract the data from a big website in a fast and reliable way.
A simple example
In this example, I’ll extract data from the website http://www.expo-guide.com/ which could be the largest repository of exhibitions listing in the field containing millions of exhibitors profiles records which are ever-growing over time. The task can be divided into 2 steps:
first, get the complete exhibitions list
get all the exhibitors associated to those exhibitions
The query can be conducted at the below selection box:
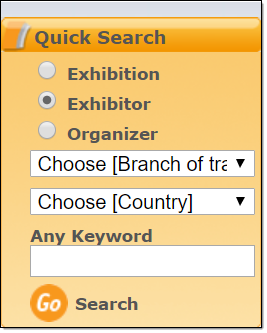
So, first select 'Exhibition', then select an industry from the drop down:
Query exhibitions list with industry(country)
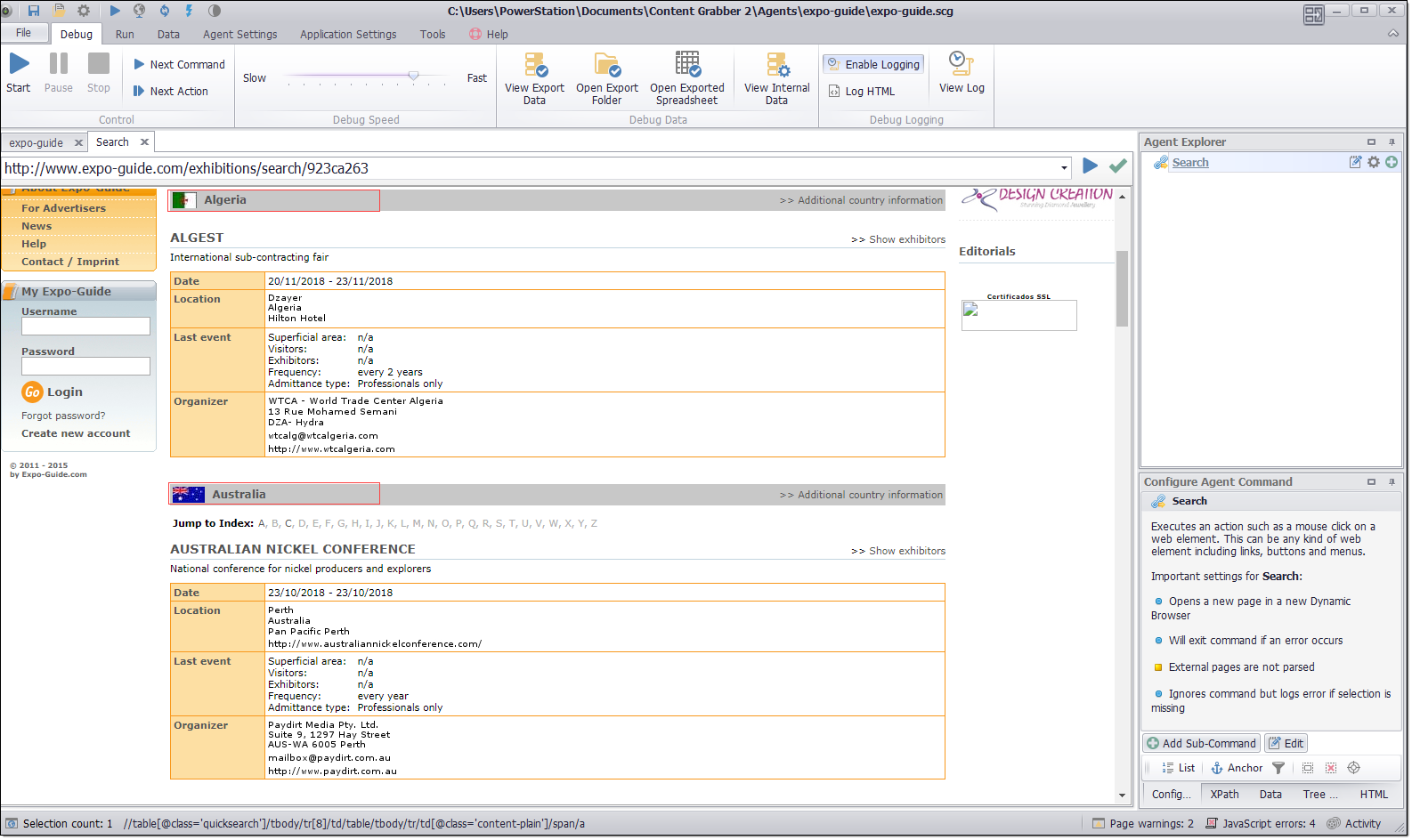
Once the Search button is clicked, the query result should appear like below:
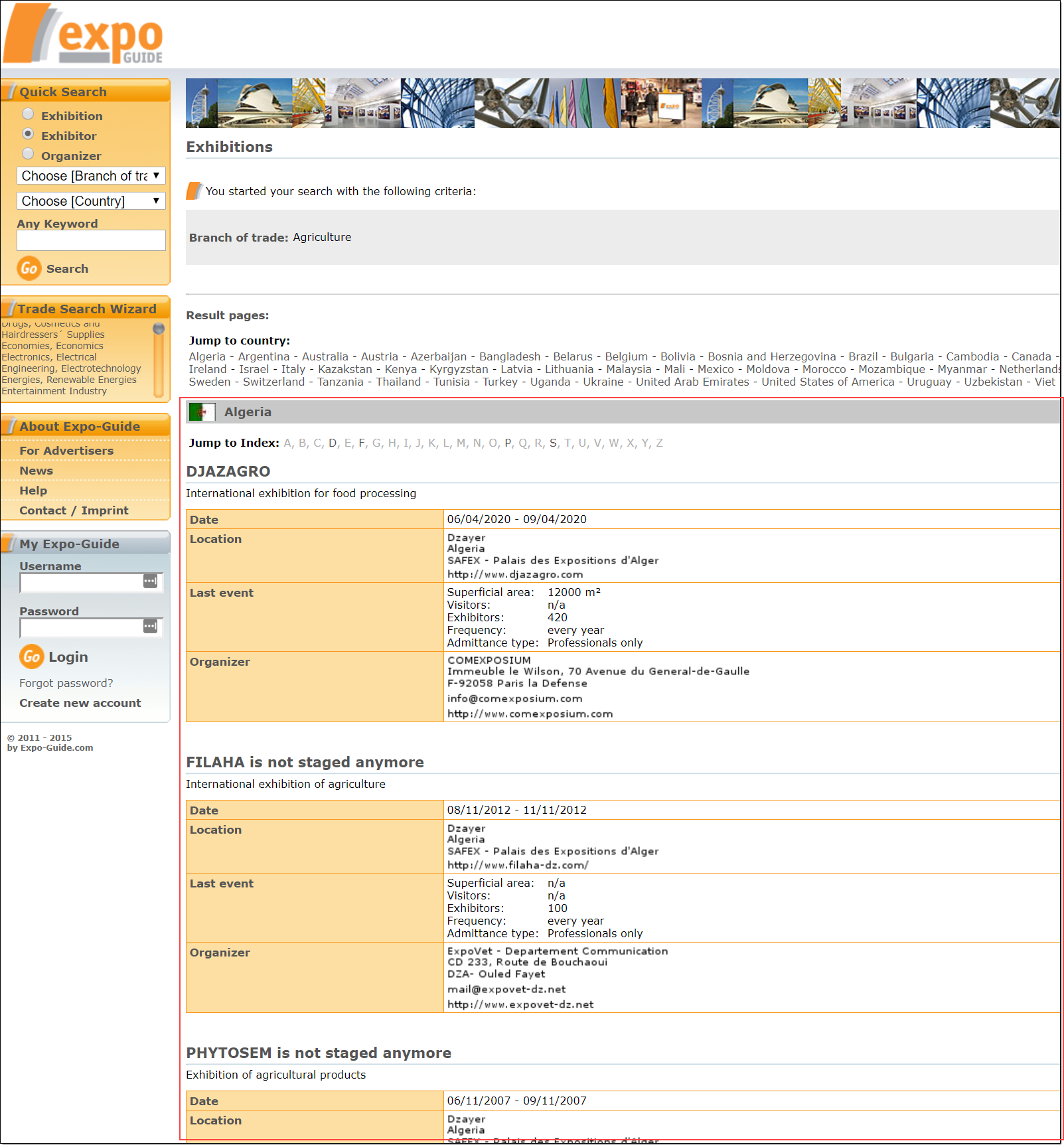
Following this extraction approach, we can now use Sequentum Enterprise to develop the agent.
When the above is complete, we are ready to run the agent.
Just wait! Let review to see if our approach makes sense before the agent starts!
As an exhibition could usually be themed with multiple industries, for example, an exhibition themed with 'Food Industry' could also be themed with 'Agriculture', and now the agent is taking the 'Industry' approach, this means the same exhibition can possibly be retrieved multiple times. The exhibitors associated to an exhibition can also be retrieved multiple times. This will result in significant duplication which will waste proxies (if applicable,) as well as other computing resources and ultimately make the extraction process unpredictably long.
We should apply the 'Remove Duplicate' command to avoid the repeated retrieval of the same exhibition records and, further on, the same exhibitors records. Problem solved!
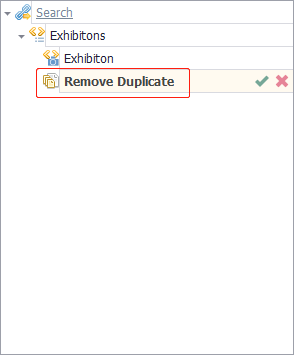
But is this the optimal extraction approach?
As we know, in real world any given exhibition can be held at a given venue once only which means, if we query the exhibitions list with location, the resultant exhibitions list will be retrieved once only. There is even no need to apply the 'Remove Duplicate' command.
Query exhibitions list with location(country)
As you can see, query exhibitions list with industry vs query exhibitions list with location (country) are two different approaches, the second approach can really benefit to:
avoid data duplicates
lesson the execution of command 'Remove Duplicate' or even avoid it
reduce the page requests
improve the agent performance.
Conclusions
When faced with a large website that can possibly host millions of web pages, doing some upfront analysis and choosing the best extraction approach first, instead of rushing to the agent development, can help speed up the extraction process greatly and avoid the lasting defects that are caused by less optimal approaches for the incremental aggregation afterwards.